Как организована информация в реляционной базе данных
Содержание:
- Схема двумерной реляционной таблицы базы данных
- Структура реляционных баз данных
- Жесткие диски цены
- Как хранится информация в БД
- Применение по прямому назначению
- Ключи
- Процесс моделирования и составления основных элементов
- Отношения или таблицы
- Хранилища данных графовGraph data stores
- История
- Реляционные операции
- Как ускорить работу компьютера (ноутбука) Windows 7
- В чём преимущества
- Хранимые процедуры
- O(1) vs O(n2)
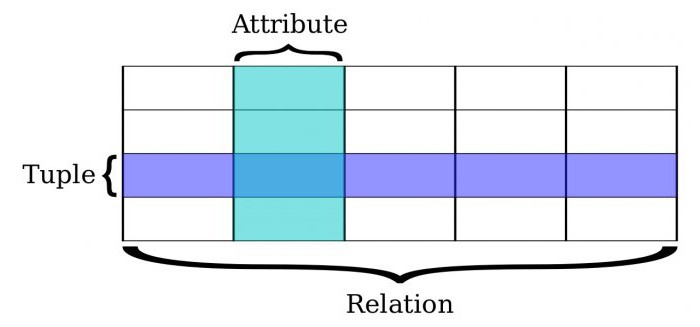
Схема двумерной реляционной таблицы базы данных
| Название атрибута 1 | Название атрибута 2 | Название атрибута 3 | Название атрибута 4 | Название атрибута 5 |
| Элемент_1_1 | Элемент_1_2 | Элемент_1_3 | Элемент_1_4 | Элемент_1_5 |
| Элемент_2_1 | Элемент_2_2 | Элемент_2_3 | Элемент_2_4 | Элемент_2_5 |
| Элемент_3_1 | Элемент_3_2 | Элемент_3_3 | Элемент_3_4 | Элемент_3_5 |
Для детального понимания системы управления модели с помощью SQL лучше всего рассмотреть схему на примере. Нам уже известно, что представляет собой реляционная БД. Запись в каждой таблице – это один элемент данных. Чтобы предотвратить избыточность данных, необходимо провести операции нормализации.
Структура реляционных баз данных
Основные термины и понятия реляционных баз данных представлены:
- отношениями — двумерными таблицами, содержащими информацию о различных объектах;
- полями таблицы — столбцами таблиц, содержащими значения, характеризуемые определенными свойствами (размер, формат данных, обязательность заполнения);
- типами данных — типами значений конкретных столбцов;
- атрибутами — заголовками столбцов таблиц, характеризующими поименованное свойство объекта;
- доменами — множеством всех допустимых значений атрибута;
- кортежами — строками таблиц, записями, состоящими из логически связанных значений атрибутов;
- ячейками — структурными элементами таблиц, задающими определенные значения соответствующих полей;
- первичными ключами — полем (или набором полей) таблицы, однозначно идентифицирующим каждую из ее записей. Набор полей называется составным ключом;
- альтернативными ключами — не совпадающими с первичным ключом полями таблицы, дающими каждой записи уникальное определение;
- внешними ключами — полем или набором полей таблицы, значения в которых совпадают со значениями первичных ключей других таблиц.
Файлы реляционной базы данных имеют свои особенности:
- каждую таблицу именуют уникальным названием;
- число полей в таблицах фиксируется;
- пересечение столбца и строки представлено только одним значением;
- записи отличаются друг от друга хотя бы одним значением элемента;
- полям присваиваются индивидуальные имена;
- в каждом столбце должны содержаться однородные данные.
Жесткие диски цены
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Применение по прямому назначению
Не следует путать БД и хранилище данных. В хранилище данные накапливаются за долгий период времени, в то время как база всё время меняет их на актуальные. Из-за этого хранилища плохо подходят под автоматизированные процессы анализа.
Неизменность данных также отличительная черта хранилища. Поэтому они предназначены для более содержательного исследования информации.
Без применения БД не обойтись при создании динамичного сайта. Если на нём несколько страниц и информация на них постоянно обновляется, потребуется автоматизация управления контентом. Данные для наполнения сайта будут содержаться и браться из базы. Таким образом содержимое страницы будет автоматически формироваться для каждого пользователя индивидуально.
Написание сайта это не только построение его реляционной базы. Для создания сайта на языке php нужно знать множество нюансов. Такие особенности и примеры решения возникающих трудностей в своих видеоуроках рассказывает Михаил Русаков. Благодаря его курсам вы сможете вывести свои навыки на более профессиональный уровень. А получая новые знания, расширите круг своих возможностей.
Подписывайтесь на обновления моего блога, тут часто появляются интересные и полезные статьи. А подписавшись на мою группу Вконтакте, вы сможете получать последние обновления прямо в свою новостную ленту.
Ключи
Каждая строка в таблице имеет свой уникальный ключ. Строки в таблице можно связать со строками в других таблицах, добавив столбец для уникального ключа связанной строки (такие столбцы известны как внешние ключи ). Кодд показал, что отношения данных произвольной сложности могут быть представлены простым набором концепций.
Часть этой обработки включает постоянную возможность выбрать или изменить одну и только одну строку в таблице. Таким образом, большинство физических реализаций имеют уникальный первичный ключ (PK) для каждой строки в таблице. Когда в таблицу записывается новая строка, создается новое уникальное значение для первичного ключа; это ключ, который система использует в первую очередь для доступа к таблице. Производительность системы оптимизирована для ПК. Другие, более естественные ключи также могут быть идентифицированы и определены как альтернативные ключи (AK). Часто для формирования AK требуется несколько столбцов (это одна из причин, по которой один целочисленный столбец обычно превращается в PK). И PK, и AK имеют возможность однозначно идентифицировать строку в таблице. Дополнительная технология может применяться для обеспечения уникального идентификатора во всем мире, глобального уникального идентификатора , когда есть более широкие системные требования.
Первичные ключи в базе данных используются для определения отношений между таблицами. Когда PK переносится в другую таблицу, он становится внешним ключом в другой таблице. Когда каждая ячейка может содержать только одно значение, а PK переносится в обычную таблицу сущностей, этот шаблон проектирования может представлять отношения « один к одному» или « один ко многим» . Большинство проектов реляционных баз данных разрешают отношения « многие-ко-многим» путем создания дополнительной таблицы, содержащей PK из обеих других таблиц сущностей — отношение становится сущностью; затем таблица разрешения именуется соответствующим образом, и два FK объединяются, чтобы сформировать PK. Миграция PK в другие таблицы — вторая основная причина, по которой целые числа, назначенные системой, обычно используются в качестве PK; обычно нет ни эффективности, ни ясности в переносе множества других типов столбцов.
Отношения
Отношения — это логическая связь между различными таблицами, установленная на основе взаимодействия между этими таблицами.
Процесс моделирования и составления основных элементов
Для того чтобы создать собственную СУБД, следует воспользоваться одним из инструментов моделирования, продумать, с какой информацией вам необходимо работать, спроектировать таблицы и реляционные одно- и множественные связи между данными, заполнить ячейки сущностей и установить первичный, внешние ключи.
Моделирование таблиц и проектирование реляционных баз данных производится посредством бесплатных инструментов, таких как Workbench, PhpMyAdmin, Case Studio, dbForge Studio. После детальной проектировки следует сохранить графически готовую реляционную модель и перевести ее в готовый SQL-код. На этом этапе можно начинать работу с сортировкой данных, их обработку и систематизацию.
Отношения или таблицы
Отношение определяется как набор кортежей , которые имеют одни и те же атрибуты . Кортеж обычно представляет объект и информацию об этом объекте. Объекты обычно представляют собой физические объекты или концепции. Отношение обычно описывается как таблица , которая организована в строки и столбцы . Все данные, на которые ссылается атрибут, находятся в одном домене и соответствуют одним и тем же ограничениям.
Реляционная модель определяет, что кортежи отношения не имеют определенного порядка и что кортежи, в свою очередь, не устанавливают порядок атрибутов. Приложения получают доступ к данным, задавая запросы, в которых используются такие операции, как выбор для идентификации кортежей, проект для идентификации атрибутов и соединение для объединения отношений. Отношения можно изменять с помощью операторов вставки , удаления и обновления . Новые кортежи могут предоставлять явные значения или быть производными от запроса. Точно так же запросы идентифицируют кортежи для обновления или удаления.
Кортежи по определению уникальны. Если кортеж содержит кандидата или первичный ключ, то, очевидно, он уникален; однако не нужно определять первичный ключ для строки или записи, которые должны быть кортежем. Определение кортежа требует, чтобы он был уникальным, но не требует определения первичного ключа. Поскольку кортеж уникален, его атрибуты по определению составляют суперключ .
Хранилища данных графовGraph data stores
Хранилища данных графов управляют сведениями двух типов: узлами и ребрами.A graph data store manages two types of information, nodes and edges. Узлы в этом случае представляют сущности, а ребра определяют связи между ними.Nodes represent entities, and edges specify the relationships between these entities. Узлы и грани имеют свойства, которые предоставляют сведения о конкретном узле или грани, примерно как столбцы в реляционной таблице.Both nodes and edges can have properties that provide information about that node or edge, similar to columns in a table. Грани могут иметь направление, указывающее на характер связи.Edges can also have a direction indicating the nature of the relationship.
Хранилища данных графов позволяют приложениям эффективно выполнять запросы, которые проходят через сеть узлов и ребер, а также анализировать связи между сущностями.The purpose of a graph data store is to allow an application to efficiently perform queries that traverse the network of nodes and edges, and to analyze the relationships between entities. На схеме ниже представлены данные персонала организации, структурированные в виде графа.The following diagram shows an organization’s personnel data structured as a graph. Сущностями здесь являются сотрудники и отделы, а грани определяют отношения подчинения и отдел, в котором работает каждый сотрудник.The entities are employees and departments, and the edges indicate reporting relationships and the department in which employees work. Стрелки на ребрах этого графа показывают направление связей.In this graph, the arrows on the edges show the direction of the relationships.
Такая структура позволяет легко выполнять такие запросы, как «найти всех сотрудников, которые прямо или косвенно подчиняются Светлане» или «найти всех, кто работает в одном отделе с Дмитрием».This structure makes it straightforward to perform queries such as «Find all employees who report directly or indirectly to Sarah» or «Who works in the same department as John?» Для больших диаграмм с большим количеством сущностей и связей можно быстро выполнять сложный анализ.For large graphs with lots of entities and relationships, you can perform complex analyses quickly. Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.Many graph databases provide a query language that you can use to traverse a network of relationships efficiently.
Соответствующие службы Azure:Relevant Azure service:
API Graph в Azure Cosmos DBAzure Cosmos DB Graph API
История
Реляционные системы берут свое начало в математической теории множеств. Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин «запись», который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин «кортеж длины n» или просто «кортеж», которому дал точное определение.
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных. Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним.
Реляционные операции
Запросы к реляционной базе данных и производные реляционные переменные в базе данных выражаются в реляционном исчислении или реляционной алгебре . В своей первоначальной реляционной алгебре Кодд ввел восемь реляционных операторов в две группы по четыре оператора в каждой. Первые четыре оператора были основаны на традиционных математических операциях над множеством :
- Оператор объединения объединяет кортежи двух отношений и удаляет все повторяющиеся кортежи из результата. Оператор реляционного объединения эквивалентен оператору SQL UNION .
- Оператор пересечения создает набор кортежей, которые являются общими для двух отношений. Пересечение реализовано в SQL в виде оператора INTERSECT .
- Оператор разности воздействует на два отношения и создает набор кортежей из первого отношения, которых нет во втором отношении. Различие реализовано в SQL в виде оператора EXCEPT или MINUS.
- Декартово произведение двух отношений является объединение , которое не ограничивается каким — либо критериям, в результате чего в каждом наборе из первого соотношения, совпадающим с каждым кортежем второго соотношения. Декартово произведение реализовано в SQL как оператор перекрестного соединения .
Остальные операторы, предложенные Коддом, включают специальные операции, характерные для реляционных баз данных:
- Операция выбора или ограничения извлекает кортежи из отношения, ограничивая результаты только теми, которые соответствуют определенному критерию, то есть подмножеству с точки зрения теории множеств. SQL-эквивалентом выбора является оператор запроса SELECT с предложением WHERE .
- Операция проецирования извлекает только указанные атрибуты из кортежа или набора кортежей.
- Операция соединения, определенная для реляционных баз данных, часто называется естественным соединением. В этом типе соединения два отношения связаны своими общими атрибутами. MySQL аппроксимация естественного соединения — это оператор внутреннего соединения . В SQL INNER JOIN предотвращает появление декартова произведения, когда в запросе есть две таблицы. Для каждой таблицы, добавленной в SQL-запрос, добавляется одно дополнительное ВНУТРЕННЕЕ СОЕДИНЕНИЕ, чтобы предотвратить декартово произведение. Таким образом, для N таблиц в запросе SQL должно быть N − 1 INNER JOINS, чтобы предотвратить декартово произведение.
- Операция является немного более сложной операцией и по существу включает в себя использование кортежей одного отношения (делимого) для разделения второго отношения (делителя). Оператор реляционного деления фактически противоположен оператору декартового произведения (отсюда и название).
Другие операторы были введены или предложены после того, как Кодд представил первоначальную восьмерку, включая операторы реляционного сравнения и расширения, которые, помимо прочего, предлагают поддержку вложенности и иерархических данных.
Как ускорить работу компьютера (ноутбука) Windows 7
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Хранимые процедуры
Большая часть программирования в РСУБД выполняется с использованием хранимых процедур (SP). Часто процедуры могут использоваться для значительного уменьшения объема информации, передаваемой внутри и вне системы. Для повышения безопасности проект системы может предоставлять доступ только к хранимым процедурам, а не напрямую к таблицам. Фундаментальные хранимые процедуры содержат логику, необходимую для вставки новых и обновления существующих данных. Могут быть написаны более сложные процедуры для реализации дополнительных правил и логики, связанных с обработкой или выбором данных.
O(1) vs O(n2)
В настоящее время многие разработчики не заботятся о временной сложности алгоритмов … и они правы!
Но когда вы имеете дело с большим количеством данных (я не говорю о тысячах) или если вы боретесь за миллисекунды, становится критически важным понять эту концепцию. И как вы понимаете, базы данных должны иметь дело с обеими ситуациями! Я не заставлю вас потратить больше времени, чем необходимо чтобы ухватить суть. Это поможет нам позже понять концепцию оптимизации на основе затрат (cost based optimization).
Концепция
Временная сложность алгоритма используется, чтобы увидеть сколько времени займет выполнение алгоритма для данного объема данных. Чтобы описать эту сложность, используют математические обозначения больших О. Эта нотация используется с функцией, которая описывает, сколько операций нужно алгоритму для заданного количества входных данных.
Например, когда я говорю «этот алгоритм имеет сложность O (some_function() )», это означает, что для обработки определенного объема данных алгоритму требуется some_function(a_certain_amount_of_data) операций.
При этом важно не количество данных**, а то, ** как увеличивается количество операций при увеличении объема данных. Сложность по времени не дает точное количество операций, но хороший способ для оценки времени выполнения
На этом графике вы можете увидеть зависимость числа операций от объема входных данных для различных типов временных сложностей алгоритмов. Я использовал логарифмическую шкалу, чтобы отобразить их. Другими словами, количество данных быстро увеличивается с 1 до 1 млрд. Мы можем увидеть, что:
- O(1) или постоянная сложность остаются постоянными (иначе это не будет называться постоянной сложностью).
- O(log(n)) остается низкой даже с миллиардами данных.
- Наихудшая сложность — O(n2), где количество операций быстро растет.
- Две другие сложности так же быстро увеличиваются.
Примеры
При небольшом количестве данных разница между O(1) и O(n2) незначительна. Например, предположим, что у вас есть алгоритм, который должен обрабатывать 2000 элементов.
- Алгоритм O (1) обойдется вам в 1 операцию
- Алгоритм O (log (n)) обойдется вам в 7 операций
- Алгоритм O (n) обойдется вам в 2 000 операций
- Алгоритм O (n * log (n)) обойдется вам в 14 000 операций
- Алгоритм O (n2) обойдется вам в 4 000 000 операций
Как я уже сказал, по-прежнему важно знать эту концепцию при работе с огромным количеством данных. Если на этот раз алгоритм должен обработать 1 000 000 элементов (что не так уж много для базы данных):
- Алгоритм O (1) обойдется вам в 1 операцию
- Алгоритм O (log (n)) обойдется вам в 14 операций
- Алгоритм O (n) обойдется вам в 1 000 000 операций
- Алгоритм O (n * log (n)) обойдется вам в 14 000 000 операций
- Алгоритм O (n2) обойдется вам в 1 000 000 000 000 операций
Я не делал расчетов, но я бы сказал, что с помощью алгоритма O (n2) у вас есть время выпить кофе (даже два!). Если вы добавите еще 0 к объему данных, у вас будет время, чтобы вздремнуть.
Идем глубже
Для справки:
- Поиск в хорошей хеш-таблице находит элемент за O (1).
- Поиск в хорошо сбалансированном дереве дает результат за O (log (n)).
- Поиск в массиве дает результат за O (n).
- Лучшие алгоритмы сортировки имеют сложность O (n * log (n)).
- Плохой алгоритм сортировки имеет сложность O (n2).
Примечание: в следующих частях мы увидим эти алгоритмы и структуры данных.
Есть несколько типов временной сложности алгоритма:
- сценарий среднего случая
- лучший вариант развития событий
- и худший сценарий
Временная сложность часто является наихудшим сценарием.
Я говорил только о временной сложности алгоритма, но сложность также применима для:
- потребления памяти алгоритмом
- потребления дискового ввода / вывода алгоритмом
Конечно, есть сложности хуже, чем n2, например:
- n4: это ужасно! Некоторые из упомянутых алгоритмов имеют такую сложность.
- 3n: это еще хуже! Один из алгоритмов, которые мы увидим в середине этой статьи, имеет эту сложность (и он действительно используется во многих базах данных).
- факториал n: вы никогда не получите свои результаты даже с небольшим количеством данных.
- nn: если вы столкнетесь с этой сложностью, вы должны спросить себя, действительно ли это ваша сфера деятельности …