Иерархические базы данных
Содержание:
- Отзывы и комментарии о сайте: cashbox.ru
- Типы баз данных
- MyISAM
- Уровни моделирования реляционной базы данных
- Историческая справка
- ПримерыExamples
- Управляющая часть иерархической модели
- Иерархия и реляционность
- Программы доступа к Webmoney
- Операции над данными
- Преобразование концептуальной модели в иерархическую модель данных
- Управляющая часть иерархической модели
- Проектирование баз данных
- Обобщенное описание структуры
- Логическое проектирование и оптимизация
- Ошибка 0xc000021a – программное обеспечение не совместимо с операционной системой
- Область применения и основные требования к канальным вентиляторам
- Иерархические
- Пример табличной базы данных
- Что такое реляционная база данных
- Поля реляционной базы данных:
- Примеры
- Как работают базы данных.
- InnoDB
- Операции над данными
- Пример модели
Отзывы и комментарии о сайте: cashbox.ru
Типы баз данных
В базах данных информация хранится, как было отмечено выше, в упорядоченном виде. В связи с этим существуют различные типы баз данных: иерархические, сетевые и табличные.
Иерархические базы данных графически представляются в виде дерева, состоящего из объектов различных уровней. На самом верхнем уровне находится один объект, на втором — объекты второго уровня и т. д.
Объекты связаны между собой, причем каждый из них может включать в себя объекты более низкого уровня. Примером иерархической базы данных является каталог папок в операционной системе Windows.
Замечание 1
Сетевую базу данных от иерархической отличает то, что в ней каждый элемент верхнего уровня может быть связан одновременно с любыми элементами следующего уровня.
Отметим, что связи между объектами в сетевых моделях не имеют никаких ограничений. Примером сетевой базы данных является Всемирная паутина глобальной сети Интернет. Миллионы документов связаны между собой при помощи гиперссылок в единую распределенную сетевую базу данных.
Табличная (реляционная) база данных представляет сбой перечень объектов одного типа, т.е. объектов с одинаковым набором свойств.
MyISAM
MyISAM – является родным типом таблиц для базы СУБД MySQL. База данных в MySQL организуется как каталог. Таблицы базы данных организуются как файлы данного каталога. Каждая MyISAM таблица хранится на диске в трех файлах, имена которых совпадают с названием таблицы, а расширение может принимать одно из следующих значений:
- Frm – содержит структуру таблицы, в файле данного типа хранится информация об именах и типах столбцов и индексов.
- Myd – файл, в котором содержатся данные таблицы.
- Myi – файл, котором содержатся индексы таблицы.
Особенности типа таблиц MyISAM:
- Данные хранятся в кросс-платформенном формате, это позволяет переносить базы данных с сервера непосредственным копированием файлов, минуя промежуточные форматы.
- Максимальное число индексов в таблице составляет 64. Каждый индекс может состоять максимум из 16 столбцов.
- Для каждого из текстовых столбцов может быть назначена своя кодировка.
- Допускается индексирования текстовых столбцов, в том числе и переменной длины.
- Поддерживается полнотекстовый поиск.
- Каждая таблица имеет специальный флаг, указывающий правильность закрытия таблиц. Если сервер останавливается аварийно, то при его повторном старте незакрытые флаги сигнализируют о возможных сбойных таблицах, сервер автоматически проверяет их и пытается восстановить.
Уровни моделирования реляционной базы данных
Внешний уровень – уровень представления базы данных с точки зрения пользователя.Концептуальный – описывает какие данные хранятся в базе данных, а также, какие связи имеются между этими данными.Внутренний – описывает физическое представление базы данных в компьютере, то есть отвечает на вопрос, как информация хранится в базе данных.
Вводятся следующие понятия:
- Модель предметной области – знания о предметной области, описанные с помощью некоторого формального общепринятого способа.
- Логическая (концептуальная) модель данных – является органической составляющей модели предметной области, описывает понятия предметной области в реляционных терминах данных.
- Физическая модель данных – описывает данные средствами конкретной реляционной СУБД.
- База данных и приложение – средства, реализованные на конкретной программно-аппаратной основе.
Историческая справка
1968 — Типичным представителем иерархических систем является Information Management System (IMS) фирмы IBM. Первая версия этого продукта вышла в свет в 1968 году. Чтобы понять иерархическую модель СУБД, попробуйте представить себе дерево (представляет собой структуру данных) со всеми его ветками и
выросшими от него другими деревьями.
1970 — Эти модели впервые предложены Е.Коддом в 1970 году в качестве наиболее независимых от аппаратных средств компьютера. Но только персональные компьютеры, мощные ресурсы которых поступают в полное распоряжение одного пользователя в отличие от больших ЭВМ, открыли дорогу реляционным СУБД. За счет некоторой избыточности сетевая и иерархическая модель могут быть сведены к табличной (реляционной) модели данных.
ПримерыExamples
Простой примерSimple Example
Следующий пример намеренно упрощен, чтобы легче было приступить к работе.The following example is intentionally simplistic to help you get started. Сначала создайте таблицу для хранения определенных географических данных.First create a table to hold some geography data.
Теперь введите данные для некоторых континентов, стран, штатов и городов.Now insert data for some continents, countries, states, and cities.
Выберите данные, добавляя столбец, который преобразовывает данные уровня в текстовое значение, удобное для восприятия.Select the data, adding a column that converts the Level data into a text value that is easy to understand. Этот запрос также отсортирует результат по типу данных hierarchyid .This query also orders the result by the hierarchyid data type.
Результирующий набор:Here is the result set.
Обратите внимание, что иерархия имеет допустимую структуру, несмотря на отсутствие внутреннего согласования.Notice that the hierarchy has a valid structure, even though it is not internally consistent. Байя — единственный штат.Bahia is the only state
Он отображается в иерархии как одноранговый по отношению к городу Бразилиа.It appears in the hierarchy as a peer of the city Brasilia. Аналогично полярная станция Макмердо не имеет родительской страны.Similarly, McMurdo Station does not have a parent country. Необходимо решить, подходит ли этот тип иерархии для использования.Users must decide if this type of hierarchy is appropriate for their use.
Добавьте еще одну строку и выберите результаты.Add another row and select the results.
Это демонстрирует наличие других возможных проблем.This demonstrates more possible problems. Киото можно ввести в качестве уровня даже при отсутствии родительского уровня .Kyoto can be inserted as level even though there is no parent level . И Лондон и Киото имеют одинаковое значение свойства hierarchyid.And both London and Kyoto have the same value for the hierarchyid. Опять-таки пользователи должны решить, подходит ли этот тип иерархии для использования, и заблокировать значения, недопустимые для использования.Again, users must decide if this type of hierarchy is appropriate for their use, and block values that are invalid for their usage.
Кроме того, в этой таблице не используется верхняя часть иерархии .Also, this table did not use the top of the hierarchy . Она была опущена, потому что общий родительский объект для всех континентов отсутствует.It was omitted because there is no common parent of all the continents. Его можно добавить путем добавления всей планеты.You can add one by adding the whole planet.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Иерархия и реляционность
Название «реляционная» произошло от английского слова «отношение». Как уже упоминалось в начале статьи, они часто выражаются таблично. Но в предыдущем пункте мы указали, что иерархическая БД также может организовывать связи, значит ли это, что и между этими двумя типами есть некая объединяющая их тонкая ниточка?
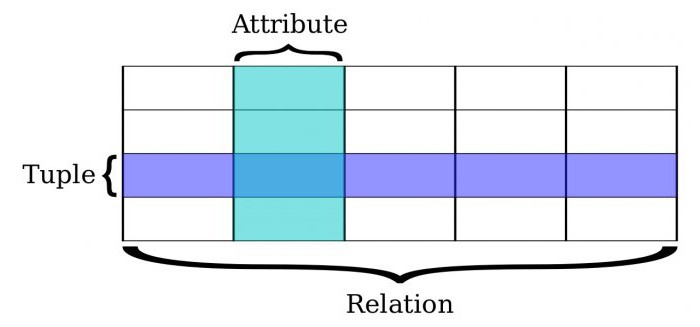
Да. Помимо того, что и первый, и второй вид все еще относятся к базам данных, кроме этого признака есть еще одно общее свойство. Например, иерархическую БД (и сетевую заодно с ней) можно выразить в таблице. Суть здесь не в том, в каком виде представить информацию конечному пользователю (это уже вопрос юзабилити интерфейса), но по какому принципу была структурирована информация. Так, четкое деление на отделы со своими начальниками, подразделениями и прочим по-прежнему будет выражено в иерархии, но для удобства занесено в таблицу.
Программы доступа к Webmoney
Операции над данными
- ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- УДАЛИТЬ некоторую запись и все подчиненные ей записи.
- ИЗВЛЕЧЬ:
— извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей
— извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева)
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб.)
Как видим, все операции изменения применяются только к одной «текущей» записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название «навигационного».
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую структуру данных во многом схоже с преобразованием её в сетевую модель, но и имеет некоторые отличия в связи с тем, что иерархическая модель требует организации всех данных в виде дерева.
Преобразование связи типа «один ко многим» между предком и потомком осуществляется практически автоматически в том случае, если потомок имеет одного предка, и происходит это следующим образом. Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
Обобщенное описание структуры
Термин «древовидная» для описания структуры упоминается в этой статье уже далеко не единожды. Пора рассказать, откуда он произошел. Все потому что иерархическая база данных — это такая БД, которая использует тип данных «дерево». Рассмотрим подробнее, что он из себя представляет.
Это составной тип: в каждый из элементов (узлов) вкладывается несколько последующих (один или более). А начинается все с одного корневого элемента. Суть в том, что каждый из кусочков типа «дерево», является подтипом, тоже «деревом». Много-много разветвленных, и все также упорядоченных структур.
Элементарные типы могут быть простыми и составными, но по существу это всегда записи. Но в простом записи присутствует один тип данных, а в составном — целая их совокупность.
Иерархической модели свойственен принцип потомков, когда каждый предыдущий сегмент является предком для последующего. Кроме того, потомок по отношению к вышестоящему типу является типом подчиненным, в то время как равнозначные один другому записи считаются близнецами.
Логическое проектирование и оптимизация
OLTP – обработка транзакций в режиме реального времени. Способ организации БД, при котором система работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом клиенту требуется от системы минимальное время отклика. Примерами OLTP приложений могут быть системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег.
Особенности OLTP приложений:
- Транзакций очень много.
- Транзакции выполняются одновременно.
- При возникновении ошибки транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета, но не поступили на другой счет).
- Все запросы к базе данных, которые должны выполняться в реальном времени, состоят из команд вставки, обновления, удаления.
OLAP системы характеризуются следующими признаками:
- Добавление в систему новых данных происходит относительно редко крупными блоками.
- Данные, добавленные в систему, обычно никогда не удаляются.
- Перед загрузкой данные проходят различные процедуры очистки, связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны
- Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного при выполнении предыдущего запроса.
- Скорость выполнения запросов важна, но не критична.
Ошибка 0xc000021a – программное обеспечение не совместимо с операционной системой
Это в равной мере относится и к программам, и к драйверам, которые могут не соответствовать требованиям Windows 10 и работать некорректно. Обратитесь к сайту производителя вашего ПО или драйвером и скачайте новую версию, возможно она уже имеет поддержку Windows 10. В любом случае старую версию программы или драйвера нужно удалить и тогда ошибки не будет.
Область применения и основные требования к канальным вентиляторам
Быстрое удаление гари из атмосферы кухни предотвращает образование сложных загрязнений на мебели, обоях, других частях интерьера. Не следует забывать и о том, что некоторые примеси способны нанести вред человеческому организму. Эффективно работающая техника устранит из санузла неприятные запахи и повышенную влажность. Такое оборудование выполняет профилактические функции, ликвидируя благоприятные условия для жизнедеятельности микроорганизмов.
Дополнительным преимуществом применения вентилятора для вытяжки является возможность дозированной подачи свежего воздуха. Она пригодится в зимний период, когда слишком интенсивное проветривание с резким понижением температуры будет провоцировать простудные заболевания. Чтобы выбрать оптимальный вариант, надо ознакомится с особенностями современных конструкций.
Следует подобрать такой вентилятор вытяжной для кухни, который будет обеспечивать необходимую производительность
Обязательно надо проверить совместимость вентилятора для вытяжки с имеющимся выходным каналом. Пригодятся:
- удобное управление;
- простой монтаж;
- отсутствие сложностей при выполнении регламентных работ в процессе эксплуатации;
- долговечность;
- минимальный уровень шумов и вибраций;
- разумная стоимость.
Иерархические
Иерархия — это когда есть вышестоящий, а есть его подчинённые, кто ниже. У них могут быть свои подчинённые и так далее. Мы уже касались такой модели, когда говорили про деревья и бустинг.
В такой базе данных сразу видно, к чему относятся записи, где они лежат и как до них добраться. Самый простой пример такой базы данных — хранение файлов и папок на компьютере:
Видно, что на диске C: есть много папок: Dropbox, eSupport, GDrive и все те, которые не поместились на экране.
Внутри папки GDrive есть ###_Inbox и #_Альбатрос, а внутри #_Альбатроса — десятки других папок. Если мы посмотрим на скриншот, то увидим, то должностная инструкция бухгалтера лежит с остальными файлами внутри папки Должностные и охрана труда, которая лежит внутри папки Инструкции.
Иерархическая база данных знает, кто кому подчиняется, и поэтому может быстро находить нужную информацию. Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Пример табличной базы данных
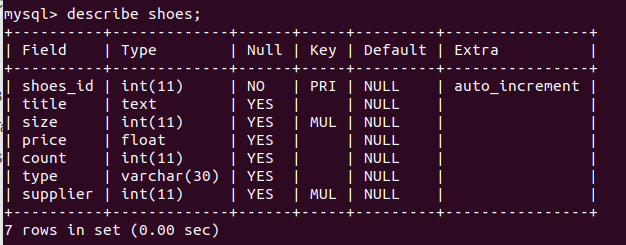
Рассмотрим базу данных «Компьютер» (рис.3), которая представляет собой перечень объектов (компьютеры), каждый из которых имеет свое имя (название). В качестве характеристик (свойств) будут выступать тип процессора и объем оперативной памяти.
Столбцы этой таблицы представляют поля, каждое из которых имеет свое имя (название соответствующего свойства) и тип данных, которые отражают значения этого свойства. Тип полей Название и Тип процессора — текстовый, а тип поля Оперативная память — числовой. При этом каждое поле имеет определенный набор свойств (размер, формат и др.). Так, для поля Оперативная память задается формат данных «целое число».
Определение 3
Полем базы данных является столбец таблицы, который включает в себя значения определенного свойства.
Строки таблицы представляют записи об объекте, которые разбиты столбцами таблицы на поля. Запись базы данных представляет собой строку таблицы, содержащую набор значений различных свойств объекта.
Замечание 3
Каждая таблица должна иметь хотя бы 1 ключевое поле, содержимое которого является уникальным для любой записи в данной таблице. Значениями ключевого поля однозначно определяются записи в таблице.
Что такое реляционная база данных
Модель базы данных определяет логический дизайн и структуру базы данных. Где реляционная база данных основана на реляционной модели и хранит данные в таблицах. Кроме того, строки представляют каждую сущность, в то время как столбцы представляют атрибуты.
Рисунок 1: Таблица в реляционной базе данных
Например, предположим, что база данных в организации. Таблица сотрудников имеет атрибуты emp-id, имя, возраст и город. Здесь первичным ключом таблицы employee является emp-id. Другая таблица называется таблицей проекта и имеет атрибуты идентификатор проекта, имя проекта, продолжительность и идентификатор emp. Здесь первичным ключом таблицы проекта является идентификатор проекта. Emp-id в таблице employee является внешним ключом в таблице проекта. Эти две таблицы связаны между собой с помощью внешнего ключа. Поэтому таблицы в реляционной базе данных связаны друг с другом.
Язык структурированных запросов (SQL) используется для хранения и управления данными в реляционной базе данных. SQL далее делится на три основные категории: язык определения данных (DDL), язык манипулирования данными (DML) и язык управления данными (DCL). Кроме того, DDL меняет структуру таблиц. DML помогает манипулировать данными, в то время как DCL помогает предоставлять и отбирать полномочия у пользователя базы данных.
Поля реляционной базы данных:
Поиск информации в базе данных Доменная система имен будет завершен и начнется поиск компьютера в сети по его IP-адресу. Вообще, на связи между объектами в сетевых моделях не накладывается никаких ограничений. Сетевой базой данных фактически является Всемирная паутина глобальной компьютерной сети Интернет.
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство.
Поиск информации в такой иерархической распределенной базе данных ведется следующим образом. Сетевая база данных является обобщением иерархической за счет допущения объектов, имеющих более одного предка. Также, трудно представить не-иерархические данные при использовании этой модели. Иерархической базой данных является Каталог папок Windows, с которым можно работать, запустив Проводник.
Примеры
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например, какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Как работают базы данных.
По сути, база данных – это набор файлов, в которых хранится информация. СУБД – система управления базами данных, управляет данными, берет на себя все низкоуровневые операции по работе с файлами, благодаря чему программист при работе с базой данных может оперировать лишь логическими конструкциями при помощи
языка программирования, не прибегая к низкоуровневым операциям.
Язык структурированных запросов SQL позволяет производить следующие операции:
- Выборку данных – извлечение из базы данных содержащейся в ней информации.
- Организацию данных – определение структуры базы данных и установления отношений между ее элементами.
- Обработку данных – добавление, изменение, удаление.
- Управление доступом – ограничение возможностей ряда пользователей на доступ к некоторым категориям данных, защита данных от несанкционированного доступа.
- Обеспечение целостности данных – защита базы данных от разрушения.
- Управление состоянием СУБД.
Достоинства системы управления базами данных MySQL:
- Скорость выполнения запросов.
- СУБД MySQL разработана с использованием языков C/C++ и оттестирована более чем на 23 платформах.
- Открытый код доступен для просмотра и модернизации всем желающим.
- Высокое качество и устойчивость работы.
- Поддержка API для различных языков программирования
- Наличие встроенного сервера. СУБД MySQL может быть использован как с внешним сервером, поддерживающим соединение с локальной машиной и с удаленным хостом, так и в качестве встроенного сервера.
- Широкий выбор типов таблиц позволяет реализовать оптимальную для решаемой задачи производительность и функциональность.
- Локализация выполнена корректна.
- Совместимость с другими базами данных и полностью удовлетворяет стандарту SQL.
InnoDB
Данный тип таблиц обеспечивает высокую производительность и устойчивое хранение данных в таблицах объемом вплоть до 1 Тбайт и нагрузкой на
сервер до 800 вставок/обновлений в секунду.Особенности таблиц типа InnoDB:
- Таблицы не создаются в базах данных, и для каждой из таблиц не выделяется отдельный файл данных. Исключение – файл определения с расширением frm, который создается по умолчанию. Все таблицы хранятся в едином табличном пространстве, поэтому имена таблиц должны быть уникальными.
- Хранение данных в едином табличном пространстве позволяет снять ограничение на объем таблиц, так как файл с таблицами может быть разбит не несколько частей и распределен по нескольким дискам или даже хостам.
- Данный тип таблиц поддерживает автоматическое восстановление после сбоев.
- Обеспечивается поддержка транзакций.
- Единственный тип таблиц, поддерживающий внешние ключи и каскадное удаление.
- Выполняется блокировка на уровне отдельных записей.
- Расширенная поддержка кодировок.
- Рушатся при достижении объема в несколько гигабайт, однако заметно уступают в скорости и не поддерживают полнотекстовый поиск.
Операции над данными
Добавление в базу данных новой записи. Корневая запись обязательно должна содержать значение ключа.
Изменение значения данных записи. Ключевые данные не должны изменяться.
Удаление некоторой записи и всех подчиненных ей записей.
Извлечение:
- корневой записи по ключевому значению, допускается также последовательный просмотр корневых записей;
- следующей записи (следующая запись извлекают в порядке левостороннего обхода дерева).
Операция извлечения допускает задать условия выборки (например, извлечение сотрудников с окладом менее 10 тысяч рублей).
Определение 5
Все операции изменения могут применяться лишь к одной «текущей» записи, предварительно извлеченной из базы данных. Такой подход к работе с данными называется навигационным.
Пример модели
Рассмотрим следующую модель данных предприятия (смотреть рисунок ниже): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры : заказчик — контракты с ним — сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. (b)).
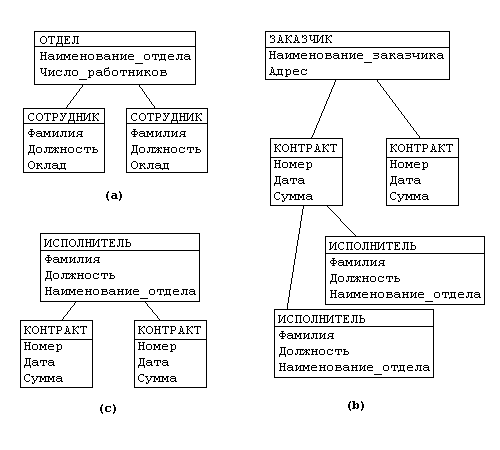
Из этого примера видны недостатки иерархических БД:
- Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
- Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ — дочерней (рис. (c)). Таким образом, мы опять вынуждены дублировать информацию.