Как определить связи между таблицами в базе данных access
Содержание:
- Для чего все это нужно?
- Роль связи многие-ко-многим
- Как определить связи между таблицами
- Мощность связи
- База данных Кинга
- Разные базы — разные правила
- Многие ко многим (many-to-many)
- Связь «Один ко многим»
- Особенности схемы данных
- Что такое мощность отношений?
- 1.2.2 Связь типа «один-ко-многим» (1:м). Ключевые поля
- Связь «Один к одному»
- Отношения “многие ко многим”: слабые отношения
- Как сделать обложку для книги в фотошопе
- Одно – многозначные связи (1:М)
- Идентифицирующая и неидентифицирующая связи
- Связь вида 1:1
- Один-ко-многим или многие-к-одному
- В чём преимущества
- Домашнее задание
- Роль связи многие-ко-многим
Для чего все это нужно?
Связи выполняют более важную роль, чем просто информация размещения данных по таблицам. Прежде всего они требуются разработчикам для поддержания целостности баз данных.
Правильно настроив связи, можно быть уверенным, что ничего не потеряется.
Представьте, что Вы решили удалить одну из групп в таблице учебной базы данных. Если бы связи не было, то для тех сотрудников, которые к ней были определены, остался идентификатор несуществующей группы. Связь не позволит удалить группу, пока она имеется во внешних ключах других таблиц. Для начала следовало определить сотрудников в другие имеющиеся или новые группы, а только затем удалить ненужную запись. Поэтому связи называют еще ограничениями.
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы мы могли развивать его дальше.
У Вас недостаточно прав для комментирования.
Роль связи многие-ко-многим
Вообще отношения между сущностями в базах данных используются для целостности информации, в них хранящейся. Только хорошо спроектированная БД со всеми необходимыми связями гарантирует безопасность хранения, удобство работы и представляет собой структуру, устойчивую к внешним воздействиям и изменениям. Обычно, если база содержит данные о целой организации, компании или фирме, в ней содержится множество сущностей с различными экземплярами.
А это значит, что при составлении схемы данных (в «Аксесе») или написании скриптов (в «Оракл» или «ДиБиТу») будет присутствовать как минимум одна связь многие-ко-многим. Пример SQl, часто использующийся при обучении курса «Организации баз данных» — БД Кинга.
Как определить связи между таблицами
При создании связи между таблицами связанные поля не должны иметь одни и те же имена. Однако связанные поля должны иметь один и тот же тип данных, если только поле первичного ключа не является полем AutoNumber. Вы можете сопоставить поле AutoNumber с полем Number, только если свойство FieldSize обоих совпадающих полей совпадает. Например, можно сопоставить поле AutoNumber и поле Number, если свойство theFieldSizeproperty обоих полей имеет значение Long Integer. Даже если оба совпадающих поля являются числовыми полями, они должны иметь параметр sameFieldSizeproperty.
Как определить связи «один ко многим» или «один к одному»
Чтобы создать связь «один ко многим» или «один к одному», выполните следующие действия.
-
Закройте все таблицы. Нельзя создавать или изменять связи между открытыми таблицами.
-
В Access 2002 и Access 2003 выполните следующие действия.
- Нажмите F11, чтобы переключиться в окно базы данных.
- В меню Инструменты выберите Связи.
В Access 2007, Access 2010 или Access 2013 нажмите Связи в группе Показать/Скрыть на вкладке Инструменты базы данных.
-
Если вы еще не определили какие-либо связи в базе данных, автоматически отобразится диалоговое окно Показать таблицу. Если вы хотите добавить таблицы, которые нужно связать, но диалоговое окно Показать таблицу не отображается, нажмите Показать таблицу в меню Связи.
-
Дважды щелкните названия таблиц, которые вы хотите связать, а затем закройте диалоговое окно Показать таблицу. Чтобы создать связь между одной и той же таблицей, добавьте эту таблицу два раза.
-
Перетащите поле, которое вы хотите связать, из одной таблицы в связанное поле в другой таблице. Чтобы перетащить несколько полей, нажмите Ctrl, нажмите на каждое поле, а затем перетащите их.
В большинстве случаев вы перетаскиваете поле первичного ключа (это поле отображается жирным текстом) из одной таблицы в аналогичное поле (это поле часто имеет одно и то же имя), которое называется внешним ключом в другой таблице.
-
Откроется диалоговое окно Изменение связей. Убедитесь, что имена полей, отображаемые в двух столбцах, верны. Вы можете изменить имена, если это необходимо.
При необходимости установите параметры связей. Если у вас есть информация о конкретном элементе в диалоговом окне Изменение связей, нажмите кнопку со знаком вопроса, а затем нажмите на элемент. (Эти параметры будут подробно описаны ниже в этой статье.)
-
Нажмите кнопку Создать, чтобы создать связь.
-
Повторите шаги с 4 по 7 для каждой пары таблиц, которые вы хотите связать.
При закрытии диалогового окна Изменение связей Access спрашивает, хотите ли вы сохранить макет. Сохраняете ли вы макет или не сохраняете макет, созданные вами связи сохраняются в базе данных.
Примечание
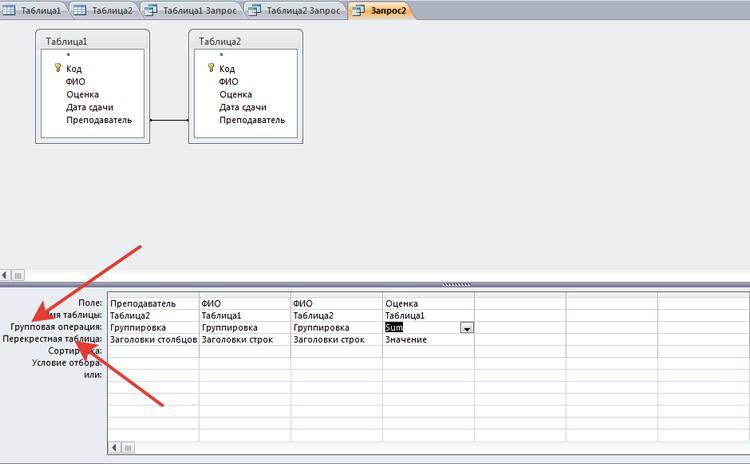
Можно создавать связи не только в таблицах, но и в запросах. Однако целостность данных связывания не обеспечивается с помощью запросов.
Как определить связь «многие ко многим»
Чтобы создать связь «многие ко многим», выполните следующие действия.
-
Создайте две таблицы, которые будут иметь связь «многие ко многим».
-
Создайте третью таблицу. Это стыковочная таблица. В таблице соединения добавьте новые поля, которые имеют те же определения, что и основные ключевые поля из каждой таблицы, созданной в шаге 1. В связующей таблице основные ключевые поля функционируют как внешние ключи. Вы можете добавить другие поля в связующую таблицу, так же, как и в любую другую таблицу.
-
В связующей таблице установите первичный ключ, чтобы включить основные ключевые поля из двух других таблиц. Например, в связующей таблице «TitleAuthors» первичный ключ будет состоять из полей OrderID и ProductID.
Примечание
Чтобы создать первичный ключ, выполните следующие действия:
-
Откройте таблицу в Конструкторе.
-
Выберите поле или поля, которые вы хотите определить в качестве первичного ключа. Чтобы выбрать одно поле, нажмите на селектор строки для нужного поля. Чтобы выбрать несколько полей, удерживайте клавишу Ctrl, а затем нажмите селектор строки для каждого поля.
-
В Access 2002 или в Access 2003 нажмите на Первичный ключ на панели инструментов.
В Access 2007 нажмите на Первичный ключ в группе Инструменты на вкладке Дизайн.
Примечание
Если вы хотите, чтобы порядок полей в первичном ключе с несколькими полями отличался от порядка этих полей в таблице, нажмите Индексы на панели инструментов для отображения диалогового окна Indexes, а затем заново упорядочите имена полей для индекса с именем PrimaryKey.
-
-
Определите связь один-ко-многим между каждой основной и связующей таблицами.
Мощность связи
Мощность
связи (Cardinality)служит для
обозначения отношения числа экземпляров
родительской сущности к числу экземпляров
дочерней.
Различают 4 типа мощности, показанные
на рис П5:
-
общий
случай, когда одному экземпляру
родительской сущности соответствуют
0, 1 или много экземпляров дочерней
сущности не помечается каким-либо
символом; -
символом
Р помечается случай, когда одному
экземпляру родительской сущности
соответствуют 1 или много экземпляров
дочерней сущности (исключено нулевое
значение); -
символом
Zпомечается случай, когда
одному экземпляру родительской сущности
соответствуют 0 или 1 экземпляр дочерней
сущности (исключены множественные
значения); -
цифрой
помечается случай точного соответствия,
когда одному экземпляру родительской
сущности соответствует заранее заданное
число экземпляров дочерней сущности.
Рис. П5. Типы мощности
База данных Кинга
Эта учебная база данных представляет собой сведения о корпорации Кинга. Среди таблиц:
- сотрудники фирмы — содержит в себе код сотрудника, его фамилию, имя и средний инициал (ориентированность на зарубежные имена), также код начальника и занимаемой сотрудником должности, дату его поступления в фирму, получаемый им оклад и предусмотренные комиссионные, код отдела;
- отделы корпорации — среди полей таблицы есть код и название отдела, а также код его размещения;
- места размещения отделов, которая предполагает внесение информации по коду места размещения и названия города;
- должности в фирме — небольшая таблица с двумя полями кода должности и ее официального названия;
- фирмы-покупатели — поля: код и название покупателя, адрес, город и штат, почтовый код и код региона, телефон, код обслуживающего покупателя менеджера, кредит для покупателя и комментарии (примечания и заметки);
- договоры о продаже, содержащая в себе код и дату договора, код покупателя, дату поставки и общую сумму договора;
- акты продаж — код акта и код договора, в который входит акт, код продукта, его цена, количество приобретенного и общая стоимость покупки;
- товары — код и название продукта;
- цены — код продукта, объявленная на него цена, минимально возможная цена,дата установления и дата отмены цены.
Небольшие таблицы, в наличии у которых не более чем два-три поля, связаны максимум с одной таблицей отношением один-к-одному или один-к-многим.
Масштабные же таблицы, такие как «сотрудники фирмы», «фирмы-покупатели», «договоры о продаже» и «акты продаж» связаны сразу с несколькими сущностями, причем с некоторыми — при помощи «посредников» отношением многие-ко-многим. Таблица «фирмы-покупатели» сама является посреднической, как таковая, ведь в ней есть многие поля, заимствованные из других таблиц и являющиеся внешними ключами. Кроме того, масштабность и взаимосвязь базы данных «Корпорации Кинга» такова, что все отношения неразрывно коррелируют между собой и влияют одно на другое. Разрушение хотя бы одного из них повлечет за собой деструкцию целостности всей БД.
Разные базы — разные правила
Внутри каждой базы данных и её управляющей системы свои строгие правила:
- какие данные могут храниться: текст, цифры, фото, видео или всё вместе;
- какие свойства есть у этих данных: дата записи, кто записал, кто может прочитать;
- что делать, если с базой хотят работать одновременно несколько человек: разрешать только одному или пусть все вместе работают.
Рабочая ситуация: допустим, вы работаете в банке и открыли карточку клиента, чтобы поменять ему кредитный лимит. В этот же момент другой сотрудник из соседнего офиса тоже хочет поменять лимит этому же клиенту, но уже на другую сумму. Как база отреагирует на такое? Должна ли она разрешать второму сотруднику открывать карточку или её нужно заблокировать, пока первый не закончит? А если она разрешит открыть карточку, то что будет, если двое сотрудников напишут там разный лимит — какой из них сохранять в итоге? СУБД задаёт эти правила и следит за их выполнением.
Многие ко многим (many-to-many)
Связь многие ко многим подразумевает, что записи в одной таблице могут иметь множество ссылок на другую таблицу и наоборот. Когда есть такой тип связи нужно создавать дополнительную таблицу, которая сведет связь многие ко многим до связи один ко многим.
Для примера предположим, обувь может быть нескольких типов (кроссовки-кеды или туфли-мокасины). Может пример и не самый удачный, однако для тренировочных целей будет то что нужно.
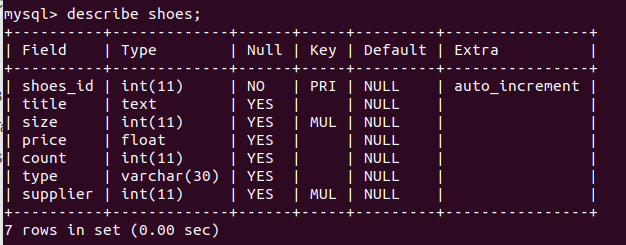
Для тех, кто все еще не понял: мы хотим чтобы поле type в таблице shoes было ссылкой на некоторую таблицу. Притом не просто ссылкой, а несколькими ссылками. На первый взгляд кажется что это не реально. Пример все пояснит.
Создаем таблицу type с полями: type_id, name:
create table type(type_id int auto_increment primary key, name text);
Теперь удаляем поле type с таблицы shoes:
alter table shoes drop type;
Далее создаем таблицу shoes_type с полями type_id, shoes_id, который будут ссылками на таблицы type и shoes соответственно.
create table shoes_type(type_id int, shoes_id int, foreign key (type_id) references type(type_id), foreign key (shoes_id) references shoes(shoes_id));
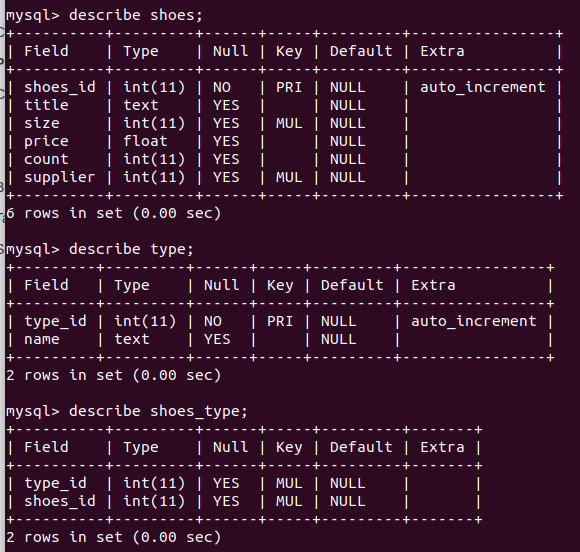
Вот так просто можно смоделировать отношение многие ко многим.
Мы не плохо так оптимизировали нашу базу данных. Желательно делать это на стадии разработки реляционной модели, а не после ее создания. Наши оптимизации местами могут показаться не совсем логичными и нужными. В данном случаи мы их делали только для изучения отношений между таблицами SQL. На деле же оптимизацию нужно проводить более тщательно. Потому что база данных — костяк (фундамент) любого приложения.
На этом пока все. Следите за новыми уроками по SQL, не забывайте учить Java и комбинируйте все это в многослойных веб приложениях.
Связь «Один ко многим»
В типе связей один ко многим одной записи первой таблицы соответствует несколько записей в другой таблице.
Рассмотрим связь учебной базы данных между должностями и сотрудниками, которая относится к рассматриваемому типу.
Записи должностей в таблице «Должность» уникальны, так как нет смысла повторно создавать имеющуюся запись. Записи в таблице «Сотрудники» также уникальны, но несколько различных сотрудников могут находиться на одинаковой должностной позиции.
Символ ключа на конце связи указывает, что таблица, к которой этой конец прилегает, находится на стороне «один» (связанный столбец является первичным ключом), а символ бесконечности находится на стороне «многие» (такой столбец является внешним ключом).
Особенности схемы данных
Реляционная база данных, которая создана соответственно проекту канонической модели данных рассматриваемой предметной области, включает только нормализованные таблицы, связанные отношениями «один-ко-многим». В подобной базе данных отсутствуют описательные данные, которые дублируются, обеспечивается их однократный ввод, поддерживается целостность данных с помощью средств системы.
С помощью связей между таблицами выполняется объединение данных разных таблиц, которое необходимо для решения многих задач введения, корректировки и просмотра данных, получения сведений по запросам и выведения отчетов. Связи таблиц устанавливаются соответственно проекту логической структуры рассматриваемой базы данных (рисунок 2) и отображаются на схеме данных Access.
Схема данных, кроме выполнения роли средства графического отображения логической структуры базы данных, активно используется в процессе обработки данных. С помощью связей, которые установлены в схеме данных, разработчик освобождается от необходимости каждый раз сообщать системе о наличии какой-либо связи. Один раз указав связи в схеме данных, они будут автоматически использоваться системой. Создание схемы данных предоставляет возможность упростить конструирование многотабличных отчетов, запросов, форм, а также обеспечивает поддержание целостности взаимосвязанных данных при корректировке и внесении данных в таблицы.
Что такое мощность отношений?
Когда вы создаете отношение между двумя таблицами, вы получаете два значения, которые могут быть 1 или * на двух концах отношения между двумя таблицами, называемые кардинальностью или мощностью отношений.
Два значения 1 или * говорят о том, что поле в этой взаимосвязи имеет определенное число значения на строку в этой таблице. Давайте проверим это на примере.
В таблице Stores у нас есть одно уникальное значение для stor_id на строку.
Таким образом, если это поле участвует в одной стороне отношения, то эта сторона примет 1 в качестве показателя кардинальности, который называется ОДНОЙ стороной отношения.
Однако stor_id в таблице Sales не уникален для каждой строки данных в этой таблице. У нас есть несколько строк для каждого stor_id. Или скажем так; в каждом магазине происходит несколько торговых транзакций (что, конечно, нормально):
Таким образом, если stor_id в таблице Sales является частью отношения, эта сторона отношения станет *, или то, что мы называем «МНОЖЕСТВЕННОЙ» стороной отношения.
Итак, основываясь на том, что мы знаем в данный момент, если мы создадим отношение на основе stor_id между двумя таблицами Sales и Stores, то получим вывод:
Эти отношения могут быть прочитаны двумя способами;
- Отношение “один-ко-многим” (1- *) из таблицы магазинов в таблицу продаж
- Отношение «многие-к-одному» (* -1) из таблицы продаж в таблицу магазинов
Они оба, конечно, одинаковы, и они будут выглядеть точно так же, как каждое из них в представлении схемы. Теперь, когда вы знаете, что такое мощность отношений, давайте изучим все виды мощности.
1.2.2 Связь типа «один-ко-многим» (1:м). Ключевые поля
При
таком типе связи каждой записи в одной
таблице соответствует одна или более
записей в связанной таблице. Для
реализации такого отношения используются
две таблицы. Одна из них представляет
сторону «один», другая — сторону «много».
Например,
нужно иметь информацию о студентах и
результатах сдачи ими экзаменов (дата
сдачи, предмет, оценка и т.д.). Если все
это хранить в одной таблице, то ее объем
неоправданно возрастет, т.к. в ней для
каждой записи об очередном экзамене
должны повторяться все анкетные сведения
о студенте. Поскольку Студент
и Экзамены
— это разные сущности, то и атрибуты их
должны храниться в разных таблицах. Но
эти сущности связаны между собой, т.к.
экзамены сдает определенный студент.
Причем один студент может сдавать
несколько экзаменов, т.е. налицо тип
отношения «один-ко-многим».
Решением
этой задачи является создание двух
таблиц
(например,
Студенты и
Экзамены),
в каждой из которых хранятся соответствующие
атрибуты (рисунок 2). Для связывания
этих таблиц нужно использовать какой-либо
атрибут студента, сдающего экзамен,
который будет повторяться в обеих
таблицах. Но этот атрибут должен
однозначно идентифицировать каждый
экземпляр сущности Студент,
т.е. являться уникальным для каждого
студента. Таким атрибутом может стать,
например, номер зачетки (он уникален
для каждого студента). В данном случае
атрибут Номер
зачетки
будет являться ключом для сущности
Студент.
Рисунок
2 Пример связи «один-ко-многим»
Ключ
– это
минимальный набор атрибутов, по значениям
которых можно однозначно найти требуемый
экземпляр сущности. Ключ может быть
простым
(когда он состоит из одного атрибута) и
составным
(когда он состоит более чем из одного
атрибута). Если в таблице нет поля,
однозначно определяющего каждую запись,
его нужно создать искусственно.
В
таблице со стороны «один» ( в нашем
примере Студенты)
поле Номер зачетки будет ключевым.
Связь «Один к одному»
Связь один к одному образуется, когда ключевой столбец (идентификатор) присутствует в другой таблице, в которой тоже является ключом либо свойствами столбца задана его уникальность (одно и тоже значение не может повторяться в разных строках).
На практике связь «один к одному» наблюдается не часто. Например, она может возникнуть, когда требуется разделить данных одной таблицы на несколько отдельных таблиц с целью безопасности.
В учебной безе данных нет подходящего примера, но гипотетически могла бы существовать необходимость разделения таблицы сотрудников.
Пример:
Представьте, что базой данных пользуются несколько менеджеров и аналитиков, а таблица «Сотрудники» содержит те же столбцы, что и учебная база. Следовательно, доступ к персональным данным может получить любой из упомянутых работников.
Чтобы устранить возможность утечки конфиденциальной информации, принимается решение о переносе информации паспортных данных в отдельную таблицу, доступ к которой предоставляется ограниченному кругу лиц.
Отношения “многие ко многим”: слабые отношения
У вас есть несколько записей для каждого значения в поле соединения между таблицами, для обеих таблиц. Если вы подумаете об этом на секунду, вы увидите, что этот сценарий происходит, когда у вас есть таблицы, которые связаны друг с другом без какого-либо общего измерения! Давайте проверим один пример. Допустим, у нас есть таблица инвентаризации фактов и таблица продаж фактов. Они обе имеют несколько записей на один продукт, и мы хотим соединить их вместе, используя идентификатор продукта. Это должно быть отношение «многие-ко-многим», потому что нет поля идентификатора продукта, в котором есть уникальные значения.
Что делать, если у вас есть более одной таблицы с этим сценарием?
Отношения «многие ко многим» вызывают массу проблем, и поэтому они также называются слабыми связями. В большинстве случаев ее можно решить путем создания общего измерения и создания отношений «один ко многим» из общего измерения с таблицами фактов. ИЗБЕГАЙТЕ такого типа отношений в вашей модели.
Лучшая модель для вышеупомянутого образца будет использовать общие размеры, как показано на этой диаграмме:
Как сделать обложку для книги в фотошопе
На компьютере можно экспериментировать, создавая папки для книг. Программа Microsoft Word позволяет это сделать. Конечно, ее возможности ниже, чем у профессиональных программ, но с ней также удастся сделать красивые переплеты. Панель рисования имеет функции, которые помогут создать папки. Автофигуры из панели можно крутить, перемещать и выбирать цвет заливки. В ворде удастся сделать упаковки, сборники и «собрать» коттедж.
Одно – многозначные связи (1:М)
Одно – многозначные связи (1:М) – это такие связи, когда экземпляру одного объекта (А) может соответствовать несколько экземпляров другого объекта (В), а каждому экземпляра второго объекта (В) может соответствовать только один экземпляр первого объекта (А).
Рис.2 Графическое изображение одно – многозначный связи отношений объектов.
В такой связи объект А является главным объектом, а объект В – подчиненным, т.е. имеет место иерархическая подчиненность объекта В объекту А. Примером одно – многозначных связей являются подразделения – сотрудники, кафедра – преподаватель, группа студент и т.п.
Идентифицирующая и неидентифицирующая связи
Связь называется идентифицирующей,
если экземпляр дочерней сущности
идентифицируется через ее связь с
родительской сущностью. Дочерняя
сущность при идентифицирующей связи
всегда является зависимой.
Связь называется неидентифицирующей,
если экземпляр дочерней сущности
идентифицируется иначе, чем через связь
с родительской сущностью. Дочерняя
сущность при неидентифицирующей связи
обычно является относительно независимой
от родительской.
Идентифицирующая связь изображается
сплошной линией; неидентифицирующая –
пунктирной линией. Линии заканчиваются
точкой со стороны дочерней сущности.
Таким образом, связи определяют, является
ли сущность независимой или зависимой.
Связь вида 1:1
Определение 2
Связь 1:1 создается, если все поля связи основной и дополнительной таблиц – ключевые.
Т.к. значения ключевых полей обеих таблиц не могут повторяться, записи из этих таблиц взаимно-однозначно соотносятся.
Пример 1
Пусть существует основная О и дополнительная Д таблицы. Символом «$*$» обозначим ключевые поля, символом «$+$» обозначим поля, которые используются для связи.
В таблицах совпадают значения в полях связи, поэтому будут связаны запись (а, 10) таблицы О и запись (а, стол) таблицы Д, а также запись (в, 3) и (в, книга).
На практике связь 1:1 используется довольно редко, т.к. информацию, которая хранится в двух таблицах, можно объединить в одну таблицу, которая будет занимать намного меньше места в памяти компьютера.
Пример 2
Например, если объединить запись (а, 10) таблицы О и запись (а, стол) таблицы Д, то получим запись (а, 10, стол) новой псевдотаблицы.
Иногда удобно иметь больше одной таблицы. Например, при необходимости ускорения обработки, повышения удобства работы с общей информацией нескольких пользователей, обеспечения большей степени защиты информации и т.д.
Один-ко-многим или многие-к-одному
Это наиболее распространенный тип мощности, используемый в моделях данных. Этот тип количества элементов означает, что одна из таблиц имеет уникальные значения в каждой строке для поля отношения, а другая имеет несколько значений. Пример, который вы видели ранее между таблицами Stores и Sales на основе stor_id, представляет собой отношение «многие-к-одному» или «один-ко-многим».
Есть два способа назвать эти отношения: один-ко-многим или многие-к-одному. Зависит от того, что является исходной и целевой таблицей.
Например, приведенная ниже конфигурация означает, что от таблицы Sales до таблицы Stores есть отношение «многие-к-одному».
А ниже показано отношение «один-ко-многим» от таблицы Stores к таблице Sales:
Эти две таблицы заканчиваются созданием таких отношений:
Это означает, что нет разницы в отношении «один-ко-многим» или «многие-к-одному», кроме порядка, в котором вы читаете это. Если вы посмотрите от таблицы Stores, у вас будет отношение «один ко многим». Если вы посмотрите на это с точки зрения таблицы Sales, у вас будет отношение «многие к одному». И оба они одинаковы, без какой-либо разницы. Так что теперь, в этой статье, всякий раз, когда вы читаете «многие к одному» или «один ко многим», вы знаете, что вы можете читать их и наоборот.
В остальной части статьи мы будем использовать термины таблиц FACT и DIMENSION, которые мы объясним отдельно в другой статье. А пока вот краткое объяснение терминов:
- Таблица фактов (FACT): таблица с числовыми значениями, которые нам нужны либо в агрегированном уровне, либо в подробном выводе. Поля из этой таблицы обычно используются в качестве раздела VALUE визуальных элементов в Power BI.
- Таблица измерений (DIMENSION): таблица, содержащая описательную информацию, которая используется для нарезки данных таблицы фактов. Поля из этой таблицы часто используются в качестве слайсеров, фильтров или осей визуалов в Power BI.
Отношение «многие к одному» между таблицами фактов и измерений
“Многие-к-одному” — это отношение, обычно используемое между таблицей фактов и таблицами измерений. Приведенный выше пример находится между таблицами Sales (таблица фактов) и Stores (таблица измерений). Если мы приведем еще одну таблицу в модель: Titles (на основе title_id в обеих таблицах: Sales и Titles), то вы увидите, что существует тот же шаблон отношений «многие-к-одному».
Этот тип отношений, хотя часто используется во многих моделях, всегда может быть предметом исследования для лучшего моделирования. В идеальной модели данных вы НЕ должны иметь отношения между двумя таблицами измерений напрямую. Давайте проверим это на примере.
Допустим, модель отличается от того, что вы видели в этом примере: таблица Sales, таблица Product и две таблицы для информации о категории и подкатегории продукта:
Как вы можете видеть на приведенной выше диаграмме отношений, все отношения — “многие-к-одному”. Что хорошо. Однако, если вы хотите нарезать данные таблицы фактов (например, SalesAmount) по полю из таблицы DimProductCategory (например, по имени ProductCategory), для обработки потребуется три отношения:
Лучшей моделью было бы объединение таблиц категорий и подкатегорий с продуктом и наличие единого отношения «многие к одному» из таблицы фактов в таблицу DimProduct. Подробнее — в ссылке выше.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Домашнее задание
Собственно задание:
- Написать SQL script создания таблицы ‘Student’ с полями: id (primary key), name, last_name, e_mail (unique).
- Написать SQL script создания таблицы ‘Book’ с полями: id, title (id + title = primary key).
Связать ‘Student’ и ‘Book’ связью ‘Student’ one-to-many ‘Book’. - Написать SQL script создания таблицы ‘Teacher’ с полями: id (primary key), name, last_name, e_mail (unique), subject.
- Связать ‘Student’ и ‘Teacher’ связью ‘Student’ many-to-many Teacher’.
- Выбрать ‘Student’ у которых в фамилии есть ‘oro’, например ‘Sidorov’, ‘Voronovsky’.
- Выбрать из таблицы ‘Student’ все фамилии (‘last_name’) и количество их повторений. Считать, что в базе есть однофамильцы. Отсортировать по количеству в порядке убывания. Выглядеть должно так:
last_name quantity Petrov 15 Ivanov 12 Sidorov 3 - Выбрать из ‘Student’ топ 3 самых повторяющихся имен ‘name’. Отсортировать по количеству в порядке убывания. Выглядеть должно так:
name quantity Alexander 27 Sergey 10 Peter 7 - Выбрать ‘Student’, у которых самое большое количество ‘Book’ и связанных с ним ‘Teacher’.Отсортировать по количеству в порядке убывания. Выглядеть должно так:
Teacher’s last_name Student’s last_name Book’s quantity Petrov Sidorov 7 Ivanov Smith 5 Petrov Kankava 2> - Выбрать ‘Teacher’, у которых самое большое количество ‘Book’ у всех его ‘Student’. Отсортировать по количеству в порядке убывания. Выглядеть должно так:
Teacher’s last_name Book’s quantity Petrov 9 Ivanov 5 - Выбрать ‘Teacher’ у которых количество ‘Book’ у всех его ‘Student’ находится между 7-ю и 11-и. Отсортировать по количеству в порядке убывания. Выглядеть должно так:
Teacher’s last_name Book’s quantity Petrov 11 Sidorov 9 Ivanov 7 - Вывести всех ‘last_name’ и ‘name’ всех ‘Teacher’ и ‘Student’ с полем ‘type‘ (student или teacher). Отсортировать в алфавитном порядке по ‘last_name’. Выглядеть должно так:
last_name type Ivanov student Kankava teacher Smith student Sidorov teacher Petrov teacher - Добавить к существующей таблице ‘Student’ колонку ‘rate’, в которой будет храниться курс, на котором студент сейчас находится (числовое значение от 1 до 6).
- Этот пункт не обязателен к выполнению, но будет плюсом. Написать функцию, которая пройдется по всем ‘Book’, и выведет через запятую все ‘title’.
Роль связи многие-ко-многим
Вообще отношения между сущностями в базах данных используются для целостности информации, в них хранящейся. Только хорошо спроектированная БД со всеми необходимыми связями гарантирует безопасность хранения, удобство работы и представляет собой структуру, устойчивую к внешним воздействиям и изменениям. Обычно, если база содержит данные о целой организации, компании или фирме, в ней содержится множество сущностей с различными экземплярами.
А это значит, что при составлении схемы данных (в «Аксесе») или написании скриптов (в «Оракл» или «ДиБиТу») будет присутствовать как минимум одна связь многие-ко-многим. Пример SQl, часто использующийся при обучении курса «Организации баз данных» — БД Кинга.