Метод split в java: делим строку на части
Содержание:
- Приоритет операторов
- 5 Тип char
- Тернарная операция
- Java Integer Math
- Сборка мусора
- Стиль оформления кода
- Следующий этап: язык C++
- Класс Java Math
- Типы с плавающей точкой
- Практическое применение побитовых операций
- Основные арифметические операции
- Запрещенные темы для публикаций
- Операция instanceof
- Библиотеки классов
- 3 Создание подстрок
- Арифметические операторы в Java
Приоритет операторов
В том случае, если в выражении есть несколько операторов – порядок их выполнения определяется приоритетом, или, другими словами, существует определённый порядок выполнения операторов.
Из школы мы знаем, что умножение в выражении выполнится раньше сложения. Это как раз и есть «приоритет». Говорят, что умножение имеет более высокий приоритет, чем сложение.
Скобки важнее, чем приоритет, так что, если мы не удовлетворены порядком по умолчанию, мы можем использовать их, чтобы изменить приоритет. Например, написать .
В JavaScript много операторов. Каждый оператор имеет соответствующий номер приоритета. Тот, у кого это число больше, – выполнится раньше. Если приоритет одинаковый, то порядок выполнения – слева направо.
Отрывок из таблицы приоритетов (нет необходимости всё запоминать, обратите внимание, что приоритет унарных операторов выше, чем соответствующих бинарных):
| Приоритет | Название | Обозначение |
|---|---|---|
| … | … | … |
| 17 | унарный плюс | |
| 17 | унарный минус | |
| 16 | возведение в степень | |
| 15 | умножение | |
| 15 | деление | |
| 13 | сложение | |
| 13 | вычитание | |
| … | … | … |
| 3 | присваивание | |
| … | … | … |
Так как «унарный плюс» имеет приоритет , который выше, чем у «сложения» (бинарный плюс), то в выражении сначала выполнятся унарные плюсы, а затем сложение.
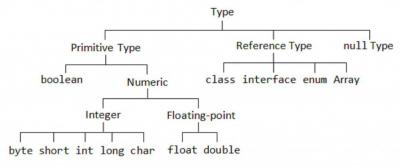
5 Тип char
Среди примитивных типов в Java есть еще один, который заслуживает особого внимания — тип . Его название происходит от слова Character, а сам тип используется для того, чтобы хранить символы.
А ведь символы — это как раз то, из чего состоят строки: каждая строка содержит в себе массив символов.
Но еще интереснее тот факт, что тип — это и числовой тип тоже! Так сказать, тип двойного назначения.
Все дело в том, что на самом деле тип хранит не символы, а коды символов из кодировки Unicode. Каждому символу соответствует число — числовой код символа.
Каждая переменная типа занимает в памяти два байта (как и тип ). Но в отличие от типа , целочисленный тип — беззнаковый, и может хранить значения от до .
Тип — гибридный тип. Его значения можно интерпретировать и как числа (их можно складывать и умножать), и как символы. Так было сделано потому, что хоть символы и имеют визуальное представление, для компьютера они в первую очередь просто числа. И работать с ними как с числами гораздо удобнее.
Unicode
Unicode — это специальная таблица (кодировка), которая содержит все символы мира. И у каждого символа есть свой номер. Выглядит она примерно так:
Присвоить значение переменной типа можно разными способами.
| Код | Описание |
|---|---|
| Переменная будет содержать латинскую букву . | |
| Переменная будет содержать латинскую букву . Ее код как раз . | |
| Переменная будет содержать латинскую букву . Ее код как раз , что равно в шестнадцатеричной системе. |
|
| Переменная будет содержать латинскую букву . Ее код как раз , что равно в шестнадцатеричной системе. Два лишних нуля ничего не меняют. |
|
| Переменная будет содержать латинскую букву . Еще один способ задать символ по его коду. |
Чаще всего просто указывают символ в кавычках (как в первой строке таблицы). Хотя популярен и последний способ. Его преимущество в том, что его можно использовать в строках.
И как мы говорили, тип — это и целочисленный тип тоже, поэтому можно написать так:
| Код | Вывод на экран |
|---|---|
| На экран будет выведена латинская буква . Потому что: – – – |
Работа с типом
Каждый символ — это в первую очередь число (код символа), а потом уже символ. Зная код символа, всегда можно получить его в программе. Пример:
| Код | Вывод на экран |
|---|---|
Стандартные коды
Вот самые известные коды символов:
| Символы | Коды |
|---|---|
| , , , … | , , , … |
| , , , … | , , , … |
| , , , … | , , , … |
Тернарная операция
Операция «?:» называется тернарной, потому что он принимает три операнда.
<выражение_boolean> ? <выражение1> : <выражение2>
| 1 | <выражение_boolean> ? <выражение1> : <выражение2> |
Тернарная операция вычисляет
<выражение_boolean>, если оно равно
true, то вычисляет и возвращает
<выражение1>, а если
false, то
<выражение2> .
Java
class Main {
public static void main(String[] args) {
int x = 3 > 2 ? 5 : -3; // 5
String str1 = 3 == 2 ? «YES»: «NO»; //»NO»
System.out.println(x);
System.out.println(str1);
}
}
|
1 |
classMain{ publicstaticvoidmain(Stringargs){ intx=3>2?5-3;// 5 Stringstr1=3==2?»YES»»NO»;//»NO» System.out.println(x); System.out.println(str1); } } |
Java Integer Math
Математические операции, выполняемые с целочисленными типами Java (byte, short, int и long), ведут себя немного иначе, чем обычные математические операции. Поскольку целочисленные типы не могут содержать дроби, в каждом вычислении с одним или несколькими целочисленными типами все дроби в результате обрезаются. Посмотрите на это математическое выражение:
int result = 100 / 8;
Результат этого деления будет 12,5, но так как два числа являются целыми числами, фракция .5 обрезается. Результат, следовательно, всего 12.
Округление также происходит в подрезультатах больших вычислений.
С плавающей точкой Math
Java содержит два типа данных с плавающей точкой: float и double. Они могут содержать дроби в числах. Если нужны дробные выражения в математических выражениях, вы должны использовать один из этих типов данных. Вот пример математического выражения с плавающей точкой:
double result = 100 / 8;
Несмотря на то, что переменная результата теперь имеет тип с плавающей запятой (double), конечный результат по-прежнему равен 12 вместо 12,5. Причина в том, что оба значения в математическом выражении (100 и 8) оба являются целыми числами. Таким образом, результат деления одного на другое сначала преобразуется в целое число (12), а затем присваивается переменной результата.
Чтобы избежать округления вычислений, необходимо убедиться, что все типы данных, включенные в математическое выражение, являются типами с плавающей запятой. Например, вы могли бы сначала присвоить значения переменным с плавающей запятой следующим образом:
double no1 = 100; double no2 = 8; double result = no1 / no2;
Теперь переменная результата будет иметь значение 12,5.
В Java есть способ заставить все числа в расчете быть переменными с плавающей точкой. Вы ставите числа с большой буквы F или D. Вот пример:
double result = 100D / 8D;
Обратите внимание на прописные буквы D после каждого числа. Этот верхний регистр D говорит Java, что эти числа должны интерпретироваться как числа с плавающей запятой, и, таким образом, деление должно быть делением с плавающей запятой, которое сохраняет дроби вместо их обрезания
На самом деле вы также можете сделать число длинным, добавив суффикс числа к верхнему регистру L, но long по-прежнему является целочисленным типом, поэтому он не будет сохранять дробные части в вычислениях.
Точность с плавающей точкой
Типы данных с плавающей точкой не являются точными на 100%. Вы можете столкнуться с ситуациями, когда числа со многими дробями не складываются с ожидаемым числом. Если вычисление с плавающей запятой приводит к числу с большим количеством дробей, чем может обработать число с плавающей запятой или двойное число, дроби могут быть обрезаны. Конечно, заданная точность может быть более чем достаточной для многих типов вычислений, но имейте в виду, что дроби могут фактически быть отсечены.
Посмотрите:
double resultDbl3 = 0D;
System.out.println("resultDbl3 = " + resultDbl3);
for(int i=0; i<100; i++){
resultDbl3 += 0.01D;
}
System.out.println("resultDbl3 = " + resultDbl3);
Вывод выводится при выполнении этого кода с Java 8:
resultDbl3 = 0.0 resultDbl3 = 1.0000000000000007
Первый оператор System.out.println() правильно печатает значение 0.0, которое является начальным значением переменной resultDbl3.
Однако второй оператор System.out.println() выводит несколько странный результат. Добавление значения 0,01 к 0 всего 100 раз должно привести к значению 1,0, верно? Но каким-то образом окончательный результат 1.0000000000000007. Как видите, что-то не так во фракциях.
Обычно неточность с плавающей запятой незначительна, но все же важно знать об этом
Сборка мусора
Обычно лексическое окружение очищается и удаляется после того, как функция выполнилась. Например:
Здесь два значения, которые технически являются свойствами лексического окружения. Но после того, как завершится, это лексическое окружение станет недоступно, поэтому оно удалится из памяти.
…Но, если есть вложенная функция, которая всё ещё доступна после выполнения , то у неё есть свойство , которое ссылается на внешнее лексическое окружение, тем самым оставляя его достижимым, «живым»:
Обратите внимание, если вызывается несколько раз и возвращаемые функции сохраняются, тогда все соответствующие объекты лексического окружения продолжат держаться в памяти. Вот три такие функции в коде ниже:. Объект лексического окружения умирает, когда становится недоступным (как и любой другой объект)
Другими словами, он существует только до того момента, пока есть хотя бы одна вложенная функция, которая ссылается на него
Объект лексического окружения умирает, когда становится недоступным (как и любой другой объект). Другими словами, он существует только до того момента, пока есть хотя бы одна вложенная функция, которая ссылается на него.
В следующем коде, после того как станет недоступным, лексическое окружение функции (и, соответственно, ) будет удалено из памяти;
Как мы видели, в теории, пока функция жива, все внешние переменные тоже сохраняются.
Но на практике движки JavaScript пытаются это оптимизировать. Они анализируют использование переменных и, если легко по коду понять, что внешняя переменная не используется – она удаляется.
Одним из важных побочных эффектов в V8 (Chrome, Opera) является то, что такая переменная становится недоступной при отладке.
Попробуйте запустить следующий пример в Chrome с открытой Developer Tools.
Когда код будет поставлен на паузу, напишите в консоли .
Как вы можете видеть – такой переменной не существует! В теории, она должна быть доступна, но попала под оптимизацию движка.
Это может приводить к забавным (если удаётся решить быстро) проблемам при отладке. Одна из них – мы можем увидеть не ту внешнюю переменную при совпадающих названиях:
До встречи!
Эту особенность V8 полезно знать. Если вы занимаетесь отладкой в Chrome/Opera, рано или поздно вы с ней встретитесь.
Это не баг в отладчике, а скорее особенность V8. Возможно со временем это изменится.
Вы всегда можете проверить это, запустив пример на этой странице.
Стиль оформления кода
Существует негласные правила оформления стиля при написании кода. Старайтесь их придерживаться. Также запоминайте оформление кода в документации и справочниках. Например, принято записывать имена классов с большой буквы (class JavaQuickCourseActivity). Если имя состоит из нескольких слов, то каждое слово в имени также начинается с большой буквы. Использовать символы подчеркивания или тире нежелательно (Java_Quick_Course_Activity или Java-Quick-Course-Activity).
Для методов и переменных используется такой же формат, только первый символ записывается с маленькой буквы, например, resultButton.
Константы принято писать только большими буквами — IDD_LIST_NAMES. В этом случае одного взгляда достаточно, чтобы сразу определить, что перед вами константа.
На первых порах вам этого достаточно.
Следующий этап: язык C++
В конце 1970-х-начале 1980-х гг. язык С стал господствующим языком программирования и продолжает широко применяться до сих пор. А если С — удачный и удобный язык, то может возникнуть вопрос: чем обусловлена потребность в каком-то другом языке? Ответ состоит в постоянно растущей сложности программ. На протяжении всей истории развития программирования постоянно растущая сложность программ порождала потребность в более совершенных способах преодоления их сложности. Язык C++ явился ответом на эту потребность. Чтобы лучше понять, почему потребность преодоления сложности программ является главной побудительной причиной создания языка C++, рассмотрим следующие факторы.
С момента изобретения компьютеров подходы к программированию коренным образом изменились. Когда компьютеры только появились, программирование осуществлялось изменением двоичных машинных инструкций вручную с панели управления компьютера. До тех пор, пока длина программ не превышала нескольких сотен инструкций, этот подход был вполне приемлем. В связи с разрастанием программ был изобретен язык ассемблера, который позволил программистам работать с более крупными и все более сложными программами, используя символьные представления машинных инструкций. По мере того как программы продолжали увеличиваться в объеме, появились языки высокого уровня, которые предоставили программистам дополнительные средства для преодоления сложности программ.
Первым языком программирования, который получил широкое распространение, был, конечно же, FORTRAN. Хотя он и стал первым впечатляющим этапом в программировании, его вряд ли можно считать языком, который способствует созданию ясных и простых для понимания программ. 1960-е годы ознаменовались зарождением структурного программирования. Эта методика программирования наиболее ярко проявилась в таких языках, как С. Пользуясь структурированными языками, программисты впервые получили возможность без особых затруднений создавать программы средней сложности. Но и методика структурного программирования уже не позволяла программистам справиться со сложными проектами, когда они достигали определенных масштабов. К началу 1980-х. сложность многих проектов начала превышать предел, позволявший справиться с ними, применяя структурный подход. Для решения этой проблемы была изобретена новая методика программирования, получившая название объектно-ориентированного программирования (ООП). Объектноориентированное программирование подробно рассматривает^ ся в последующих главах, а здесь приводится лишь краткое его определение: ООП — это методика программирования, которая помогает организовывать сложные программы, применяя принципы наследования, инкапсуляции и полиморфизма.
Из всего сказанного выше можно сделать следующий вывод: несмотря на то, что С является одним из лучших в мире языков программирования, существует предел его способности справляться со сложностью программ. Как только размеры программы превышают определенную величину, она становится слишком сложной, чтобы ее можно было охватить как единое целое. Точная величина этого предела зависит как от структуры самой программы, так и от подходов, используемых программистом, но начиная с определенного момента любая программа становится слишком сложной для понимания и внесения изменений, а следовательно, неуправляемой. Язык C++ предоставил возможности, которые позволили программистам преодолеть этот порог сложности, чтобы понимать крупные программы и управлять ими.
Язык C++ был изобретен Бьярне Страуструпом (Bjarne Stroustrup) в 1979 г., когда он работал в компании Bell Laboratories в городе Мюррей-Хилл, шт. Нью-Джерси. Вначале Страуструп назвал новый язык “С with Classes” (С с классами). Но в 1983 г. это название было изменено на C++. Язык C++ расширяет функциональные возможности языка С, добавляя в него объектно-ориентированные свойства. А поскольку язык C++ построен на основе С, то в нем поддерживаются все функциональные возможности, свойства и преимущества С. Это обстоятельство явилось главной причиной успешного распространения C++ в качестве языка программирования. Изобретение языка C++ не было попыткой создать совершенно новый язык программирования. Напротив, все усилия были направлены на усовершенствование уже существующего очень удачного языка.
Класс Java Math
Класс Java Math предоставляет более сложные математические вычисления, чем те, которые предоставляют базовые математические операторы Java. Класс Math содержит методы для:
- нахождения максимального или минимального значений;
- значений округления;
- логарифмических функций;
- квадратного корня;
- тригонометрических функций (sin, cos, tan и т. д.).
Math находится в пакете java.lang, а не в пакете java.math. Таким образом, полное имя класса Math — это java.lang.Math.
Поскольку многие его функции независимы друг от друга, каждый метод будет объяснен в своем собственном разделе ниже.
Типы с плавающей точкой
Числа с плавающей точкой (иногда их называют действительными числами) применяются при вычислении выражений, в которых требуется точность до десятичного знака. Например, это может быть вычисление квадратного корня, значений синуса, косинуса и т.п. Существует два типа с плавающей точкой: float и double, которые представляют числа одинарной и двойной точности.
Слово «плавающая» означает, что десятичная точка может располагаться в любом месте (она «плавает»). Вот коты плавать не особенно любят, поэтому они не float и не double.
Тип float
Тип float определяет значение одинарной точности, которое занимает 32 бит. Переменные данного типа удобны, когда требуется дробная часть без особой точности, например, для денежных сумм.
Рекомендуется добавлять символ F или f для обозначения этого типа, иначе число будет считаться типом double.
Конвертируем из строки.
Класс Float является оболочкой для данного типа. Без необходимости не используйте в Android класс Float.
Также есть специальный класс BigDecimal для проведения арифметических действий повышенной точности (финансовые расчёты).
Тип double
Тип double обеспечивает двойную точность, что видно из его названия (double — двойная). Занимает 64 бит для хранения значений. Многие математические функции возвращают значения типа double. Кстати, современные процессоры оптимизированы под вычисления значений двойной точности, поэтому они предпочтительнее, чем тип float.
Тип double содержит не только числа, но и слова. Сейчас вам докажу. Разделим число типа double на ноль. Ошибки не произойдёт.
Пример вернёт значение Infinity (Бесконечность). Если разделить отрицательное число на ноль, то вернётся -Infinity.
А что произойдёт, если сложить две бесконечности? Если рассуждать логически, то сломается интернет, наступит конец света или можно вызвать Волдеморта. Я долго не решался, но потом набрался храбрости и попробовал.
Вернулось ещё одно слово — NaN. Что это вообще? Может должно вернуться Nyan — ну вы знаете, это странный котик, который летит бесконечно в космосе, оставляя за собой шлейф из радуги.
Умножать две бесконечности я побоялся. И вам не советую.
Класс Double является оболочкой для данного типа. Без необходимости не используйте в Android класс Double.
Конвертация double в строку
При работе с числами double следует держать ухо востро. Рассмотрим пример конвертации трёх чисел.
Первые два числа нормально преобразовались, а вот третье число преобразовалось в строку в странном виде (на самом деле это научное представление числа). И это может источником проблемы при передаче строки куда-нибудь, например, на сервер. Если сервер не ожидает от вас такой подлости, то будет генерировать ошибки из-за странной записи. Нужно найти другие способы конвертации.
Первый способ — используем String.format().
Последний пример самый подходящий для нас, но вам нужно знать, сколько знаков идёт после десятичной точки. Остальные два пригодятся, если число можно округлить.
Второй способ — метод Double.toString(). У меня метод превратил число в «непонятную» строку. А у некоторых этот пример возвращал строку в нормальном виде. Не заслуживает доверия.
Третий способ — добавить пустую строку. В Android не помогло, хотя тоже утверждается, что у кого-то выводится в нормальном виде. Врут, наверное.
Четвёртый экзотический способ, которым редко пользуются — DecimalFormat.
Практическое применение побитовых операций
Побитовые операции имеют довольно широкое практическое применение, рассмотрим некоторые случаи:
4.3. Шифрование числа
Операция XOR при применении два раза к одному и тому же битовому массиву восстанавливает ее исходное значение. Это можно использовать при шифровании данных при передаче по сети:
C = A ^ B
A = C ^ B
Представьте, что необходимо отправить в сообщении число 560 — пин-код от банковской карты. Если злоумышленник перехватит сообщение, то узнает пин-код и сможет воспользоваться им. Только отправитель и получатель могут знать пин-код. Чтобы этого не произошло, придумаем какое-то число — маску и сообщим его получателю заранее. Перед отправкой пин-кода, зашифруем его — применим побитовую операцию XOR: . И результат отправим. Если злоумышленник и перехватит сообщение, он не будет знать как его расшифровать. Адресат получает сообщение, расшифровывает пин-код с помощью имеющейся маски: .
Следующий код иллюстрирует этот пример:
4.4. Наложение маски
Маска позволяет получать значения только определенных битов в последовательности. Например, у нас есть маска 00100100. Она позволяет нам получать из последовательности только те биты, которые в ней установлены. В данном случае это 3-й и 7-й разряд. Для этого достаточно выполнить побитовое AND с нашей маской и выбранным числом:
Основные арифметические операции
В следующей таблице перечислены основные арифметические операции, применяемые в языке Java:
Рассмотрим некоторые правила работы с арифметическими операциями:
- Выражения вычисляются слева направо, если не добавлены круглые скобки или одни операции имеют более высокий приоритет.
- Операции *, /, и % имеют более высокий приоритет чем + и -.
Пример 1. Арифметические операции над целочисленными значениями
Например, в этом коде, переменные a
и b
будут иметь разные значения:
Public class BasicIntMath {
public static void main(String args) {
int a = 4 + 5 — 2 * 3;
int b = 4 + (5 — 2) * 3;
System.out.println(«a = » + a);
System.out.println(«b = » + b);
}
}
Результат выполнения:
A = 3
b = 13
- Операция унарного вычитания изменяет знак своего единственного операнда.
- Операция унарного сложения просто возвращает значение своего операнда. Она в принципе не является необходимой, но возможна.
Пример 2. Унарные операции сложения и вычитания
Когда операция деления выполняется над целочисленным типом данных, ее результат не будет содержать дробный компонент.
Пример 3. Деление целочисленных чисел
Результат выполнения этой программы:
Операнды арифметических операций должны иметь числовой тип. Арифметические операции нельзя выполнять над логическими типами данных, но допускается над типами данных char
, поскольку в Java этот тип, по существу, является разновидностью типа int
.
Результат выполнения:
N
111
22
Пример 5. Арифметические операции над переменными типа char
Результат выполнения:
Оператор деления по модулю — обозначается символом %. Этот оператор возвращает остаток от деления первого числа на второй. При делении целого числа результатом будет тоже целое число.
Запрещенные темы для публикаций
Операция instanceof
Классы я пока здесь не описал, но эту операцию невозможно объяснить без них. Операция
instanceof проверяет, является ли объект экземпляром класса или экземпляром дочернего класса или экземпляром класса, реализующего интерфейс.
Java
obj1 instanceof A
| 1 | obj1 instanceofA |
Возвращается
true, если
obj1 не
null и является экземпляром класса
A или экземпляром дочернего класса
A или экземпляром класса, реализующего интерфейс
A.
Java
Object obj1 = new String(«test1»);
if (obj1 instanceof String) {
System.out.println(«YES»);
}
|
1 |
Objectobj1=newString(«test1»); if(obj1 instanceofString){ System.out.println(«YES»); } |
Если левый операнд равен
null, то результатом будет
false. Код ниже выведет “NO”:
Java
Object obj1 = null;
if (obj1 instanceof String) {
System.out.println(«YES»);
} else {
System.out.println(«NO»);
}
|
1 |
Objectobj1=null; if(obj1 instanceofString){ System.out.println(«YES»); }else{ System.out.println(«NO»); } |
Библиотеки классов
Библиотеки классов Java является стандартной библиотекой , разработанной для поддержки разработки приложений на Java. Он контролируется Oracle в сотрудничестве с другими через программу Java Community Process . Компании или отдельные лица, участвующие в этом процессе, могут влиять на проектирование и разработку API. Этот процесс был предметом споров в течение 2010-х годов. Библиотека классов содержит такие функции, как:
- Основные библиотеки, которые включают:
- Отражение
- Параллелизм
- Дженерики
- Скрипты / компилятор
- Функциональное программирование (Lambda, Streaming)
- Библиотеки коллекций, которые реализуют структуры данных, такие как списки , словари , деревья , наборы , очереди и двусторонние очереди или стеки
- Библиотеки обработки XML (синтаксический анализ, преобразование, проверка)
- Безопасность
- Библиотеки интернационализации и локализации
- Библиотеки интеграции, которые позволяют автору приложения взаимодействовать с внешними системами. Эти библиотеки включают:
- Java Database Connectivity (JDBC) API для доступа к базам данных
- Интерфейс именования и каталогов Java (JNDI) для поиска и обнаружения
- RMI и CORBA для разработки распределенных приложений
- JMX для управления и мониторинга приложений
-
Библиотеки пользовательского интерфейса , которые включают:
- (Тяжелый или собственный ) Abstract Window Toolkit (AWT), который предоставляет компоненты графического интерфейса , средства для размещения этих компонентов и средства для обработки событий из этих компонентов.
- (Легкие) библиотеки Swing , которые построены на AWT, но предоставляют (неродные) реализации виджетов AWT
- API для захвата, обработки и воспроизведения звука
- JavaFX
- Зависящая от платформы реализация виртуальной машины Java, которая является средством, с помощью которого выполняются байт-коды библиотек Java и сторонних приложений.
- Плагины, которые позволяют запускать апплеты в веб-браузерах.
- Java Web Start , который позволяет эффективно распространять Java-приложения среди конечных пользователей через Интернет.
- Лицензирование и документация
3 Создание подстрок
Кроме сравнения строк и поиска подстрок, есть еще одно очень популярное действие — получение подстроки из строки. В предыдущем примере вы как раз видели вызов метода , который возвращал часть строки.
Вот список из 8 методов получения подстрок из текущей строки:
| Методы | Описание |
|---|---|
| Возвращает подстроку, заданную интервалом символов . | |
| Повторяет текущую строку n раз | |
| Возвращает новую строку: заменяет символ на символ | |
| Заменяет в текущей строке подстроку, заданную регулярным выражением. | |
| Заменяет в текущей строке все подстроки, совпадающие с регулярным выражением. | |
| Преобразует строку к нижнему регистру | |
| Преобразует строку к верхнему регистру | |
| Удаляет все пробелы в начале и конце строки |
Вот краткое описание существующих методов:
Метод
Метод возвращает новую строку, которая состоит из символов текущей строки, начиная с символа под номером и заканчивая . Как и во всех интервалах в Java, символ с номером в интервал не входит. Примеры:
| Код | Результат |
|---|---|
Если параметр не указывается (а так можно), подстрока берется от символа beginIndex и до конца строки.
Метод
Метод repeat просто повторяет текущую строку раз. Пример:
| Код | Результат |
|---|---|
Метод
Метод возвращает новую строку, в которой все символы заменены на символ . Длина строки при этом не меняется. Пример:
| Код | Результат |
|---|---|
Методы и
Метод заменяет все вхождения одной подстроки на другую. Метод заменяет первое вхождение переданной подстроки на заданную подстроку. Строка, которую заменяют, задается регулярным выражением. Разбирать регулярные выражения мы будем в квесте Java Multithreading.
Примеры:
| Код | Результат |
|---|---|
Методы
С этими методами мы познакомились, когда только в первый раз учились вызывать методы класса .
Метод
Метод удаляет у строки пробелы с начала и с конца строки. Пробелы внутри строки никто не трогает. Примеры:
| Код | Результат |
|---|---|
Арифметические операторы в Java
Для стандартных арифметических операций, таких как сложение, вычитание, умножение, деление в Java используются традиционные символы, к которым мы привыкли со школы:
Примечание: при операции деления, если оба аргумента являются целыми числами, то в результате получим целое число. Дробная часть, если такая имеется, отбросится. Если хотим получить число с дробной частью, то нужно, чтобы один из аргументов был типа double. Это можно указать в самом выражении при помощи добавления после числа .0 или .d. Пример:
В Java также имеется специальный оператор %, обозначающий остаток от делния.
Пример использования: дан массив целых чисел, вывести на консоль только те числа, которые делятся на 3.
Операции с присваиванием
Рассмотрим задачу вывода на экран 10 первых четных чисел чисел
строку
мы можем записать сокращенно
+= это оператор сложения с присваиванием. Подобные операторы есть для всех основных 5 операций, рассмотренных выше
Пример использования: Найти факториал числа 7.
Инкрементирование и декрементирование
Инкремент, обозначается ++ и увеличивает значение переменной на единицу. Декремент обозначается — и уменьшает значение на единицу. С инкрементом и декрементом мы часто встречаемся в цикле for.
Инкремент и декремент бывают двух форм
Префиксная форма:
Постфиксная форма
Различие префиксной и постфиксной формы проявляется только тогда, когда эти операции присутствуют в выражениях. Если форма префиксная, то сначала произойдет увеличение (или уменьшение) переменной на единицу, а потом с новым значением будет произведены дальнейшие вычисления. Если форма постфиксная, то расчет выражения будет происходить со старым значением переменной, а переменная увеличится (или уменьшится) на единицу после вычисления выражения. Пример
В первом случае сначала переменная a увеличится на 1, потом произойдет вычисление всего выражения. Во втором случае произойдет вычисление выражения при старом значении b = 3, и после вычисления b увеличится на 1, на результат в postfix это уже не повлияет.
Если вы поняли принцип работы постфиксного и префиксного инкремента/декремента, то предлагаю решить в уме такую задачу:
Вопрос: чему в итоге равны x и y? После того, как вы сделали предположение, проверьте его в java.
Задача со зведочкой. Дан код:
Какие числа будут выведены на экран? Почему? Разобраться самостоятельно.
Примечание: инкремент и декремент применяются только к переменной. Выражение вида 7++ считается недопустимым.