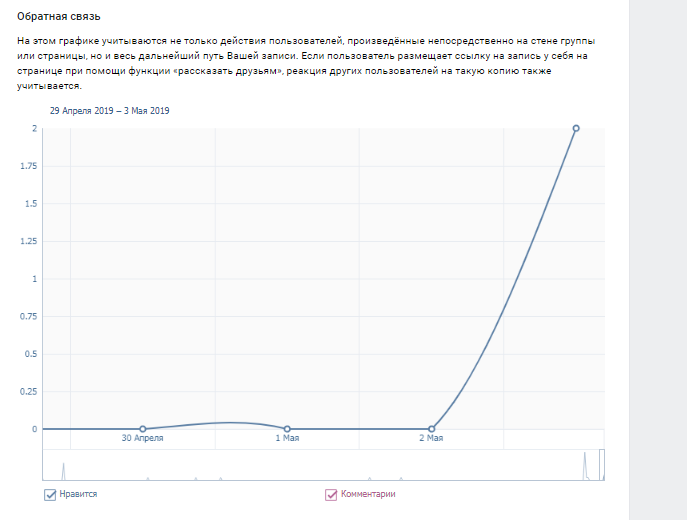
Как посмотреть, как раньше выглядела страница вконтакте
Содержание:
- Просмотр кэша страницы вручную
- Как посмотреть историю сайта
- JS Examples
- Индексация веб-страниц в интернете
- Как восстановить сайт из бэкапа?
- Как посмотреть, как выглядела страница ВКонтакте раньше
- Как удалить сайт из кэша
- Этап первый: Файловая структура
- r-tools.org
- archive.md
- Статьи
- Что такое веб-архив и зачем он нужен?
- Онлайн сервисы для копирования простых сайтов
- А теперь подробно
- Как копировать текст: интересные способы и приёмы
- 1. Просто перепечатать, когда не могу скопировать текст с сайта
- 2. Как скопировать текст, если он не копируется с помощью открытия HTML
- 3. Сделать скриншот и пропустить через онлайн сервис для распознавания текста
- 4. Как копировать текст помощью Microsoft Word (Макрософт Ворд).
- 5. Как скопировать текст помощью отключения java-скриптов
Просмотр кэша страницы вручную
В Google
На странице с выдачей (SERP) следует навести мышку на конкретный результат выдачи и кликнуть «Сохраненная копия»:
Просмотр кэшированного документа в Google
Естественно, запрос можно сформировать как угодно. На картинке приведён пример просмотра кэша конкретной страницы — http://web-ru.net/category/internet/.
404 в Google
У каждой из этих 4-х поисковых систем сверху можно обнаружить надпись вроде такой «по состоянию на 9 окт 2012 15:13:22 GMT». Т.е. отображается веб-страница такой, какой она была 9 октября 2012 года.
Кэш в Яндексе
Смысл тот же: вводим запрос, наводим курсор на один из результатов выдачи и кликаем на «Копия»:
Посмотрим кэш страницы в Яндекс
Нужно кликнуть на маленькую стрелочку, расположенную около URL-адреса страницы:
Кэш документав Bing.com
В Mail.ru
В этой поисковой системе лучше смотреть кэш отдельных страниц, а не, например, категорий. Просто потому что в Мэйле при запросе, содержащем URL категории, могут быть выведены ссылки на несколько статей этой категории, а не на саму категорию. Хотя Mail.ru как поисковик пока особо не интересен, и можно об этом вообще не думать. Ну а в целом, всё то же:
Кэш документа сайта в Mail.ru
Кстати, если в Гугле, Яндексе и Bing ввести «человеческий» запрос и посмотреть кэшированный документ, то этот запрос будет выделен на открытом сайте жёлтым цветом. Примерно так:
Выделенный запрос в кэше страницы в Гугле
Это может быть способом посмотреть, например, как оптимизированы тексты на сайтах ваших конкурентов
Таким образом, зная дату и время занесения страницы в кэш Google, Yandex и т.д. можно понять, известно ли поисковой системе о произошедших на ней изменениях или пока ещё нет.
Случайные публикации:
- Как не проиграть в SEO войне. Обзор SEO программы Netpeak spiderSEO войны это не миф, а абсолютная реальность. Каждый день, каждый час…
- Конкурс депозитов от Binpartner.com 2017…ртнерской программе от компании BinPartner будет проводиться
- Поведенческие факторы поисковых систем. Как улучшить ПФ и в чём суть?После проведённого онлайн-семинара по продвижению сайта в поиск…
- Как отключить/включить куки в браузерах Firefox, Explorer, Opera, Chrome. Должны ли быть куки отключены?Это дополнение к статье о просмотре и удалении cookies в разных…
- Как заработать на TeaserNet?Без тизерных сетей, уже невозможно представить жизнь интернета. Эти рекламные объявле…
Оставьте комментарий:
Как посмотреть историю сайта
Конечно, после выполнения модернизации сайта есть желание его сравнить с теми версиями сайта, которые были раньше. Но если не знаешь, возникает вопрос, как посмотреть историю сайта, где её посмотреть? На помощь может прийти сервис archive.org. На сервисе archive.org собрано более, чем пол триллиона сайтов. Причем, каждый сайт (блог) представлен там, в различный период времени.
Например, Вы открываете сайт и хотите посмотреть, как он выглядел в феврале 2013 года. Вы действительно его увидите таким, каким он был в тот период времени. Опубликованные на блоге статьи сможете открыть и прочитать их, даже если автор эти статьи уже удалил. Вы можете проверить историю сайта за каждый месяц, за каждый год. Представляете, какой объём информации хранит сервис archive.org!
Многие люди пишут на форумах — archive.org заблокирован, как зайти? Действительно, если просто зайти по адресу первого сайта, то сервис archive.org почему то работает не корректно.
Итак, открывается окно сервиса archive.org, далее в поле нужно ввести доменное имя своего сайта и нажать кнопку «Browse history». Теперь выбираем дату архивирования своего сайта из встроенного календаря, сначала выбираем год, далее месяц и день.
День нужно выбирать тот, который отмечен голубым кружочком – нажимаем на дату. Теперь можем посмотреть историю нашего ресурса. Мы можем посмотреть историю сайта своего или чужого. А сейчас можете посмотреть видео, как узнать историю ресурса с помощью сервиса archive.org:
JS Examples
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
Как восстановить сайт из бэкапа?
Теперь давайте рассмотрим такую ситуацию что не дай бог Ваш сайт был атакован или произошел простой сбой до пустим при обновлении движка сайта или установки расширения. Процедура аналогична той что и сохранение только тут уже нам необходимо будет заливать наши файлы. Перед заливкой файлов ручным способом или через хостинг обязательно в корне своего сайта и базы данных удалить старые файлы, а не записывайте поверх них, это может привезти к глюкам.
Для того чтобы нам залить базу данных мы как и говорилось выше заходим в “базы данных” введя логин и пароль. В самой базе находим кнопку структура, спукаемся курсором вниз таблицы и выбираем “отметить все” далее из выпадающего списка выбираем “удалить”, чтобы никакие старый файлы не мешали нашу дальнейшую работу и не вступали в конфликт с остальными файлами.
Ну вот остался последний штрих и установить нашу mysql бэкап базы которую мы копировали на компьютер. Для этого все там же в верхней части выбираем “импорт” и выбираем нашу базу на жестком диске компьютера
Обратите внимание размер базы данных не должен превышать 1 Мб в противном случае вы получите сообщение об ошибки. Если база превышает допустимый размер советую закинуть ее в архив .zip и тем самым размер сожмется и вы спокойно все сможете залить
В итоге как Вы поняли лучше побеспокоиться о безопасности своего сайта как можно раньше. Ведь как говорится кто владеет информацией – тот покорит мир. =))))))
Надеюсь материал будет полезен моим дорогим читателям и поможет в дальнейшей работе.
Если кому то будет интересна данная тема для глубокого изучения, то рекомендую видео курс с подробным описанием оригинального метода копирования данных своих проектов.
Буду благодарен за нажатии кнопочек и репост данного материала. Увидимся в следующих статьях. Всем удачи.
Как посмотреть, как выглядела страница ВКонтакте раньше

Пользовательские страницы ВКонтакте, включая и ваш персональный профиль, часто меняются под влиянием тех или иных факторов. В связи с этим становится актуальной тема просмотра раннего внешнего вида страницы, и для этого необходимо использовать сторонние средства.
Смотрим, как выглядела страница раньше
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Подробнее: Как открыть стену ВК
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
Подробнее: Поиск без регистрации ВК
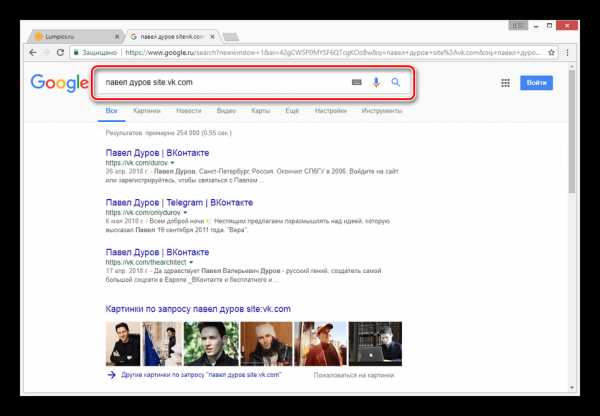
Среди представленных результатов отыщите нужный и кликните по иконке с изображением стрелочки, расположенной под основной ссылкой.
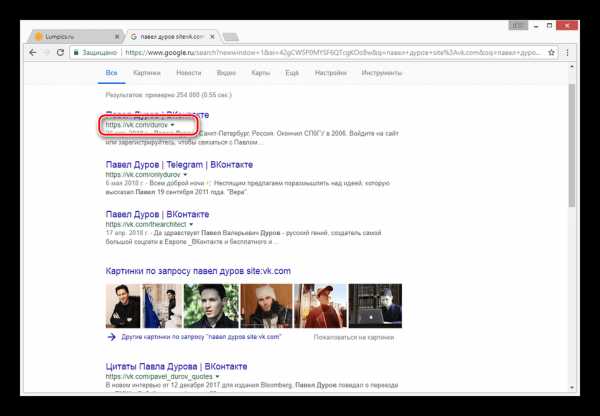
Из раскрывшегося списка выберите пункт «Сохраненная копия».
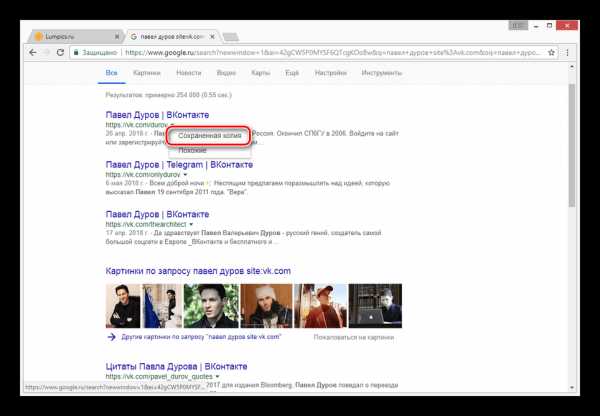
После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
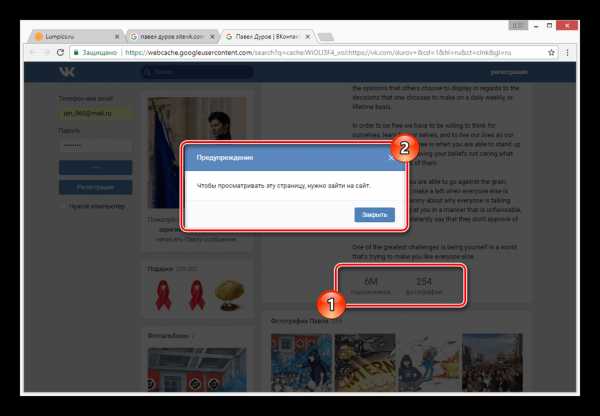
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
Перейти к официальному сайту Internet Archive
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Способ 3: Web Archive
Данный сайт является менее популярным аналогом предыдущего ресурса, но со своей задачей справляется более чем хорошо. Кроме того, вы всегда можете воспользоваться этим веб-архивом, если ранее рассмотренный сайт по каким-либо причинам оказался временно недоступен.
Перейти к официальному сайту Web Archive
- Открыв главную страницу сайта, заполните основную поисковую строку ссылкой на профиль и нажмите кнопку «Найти».
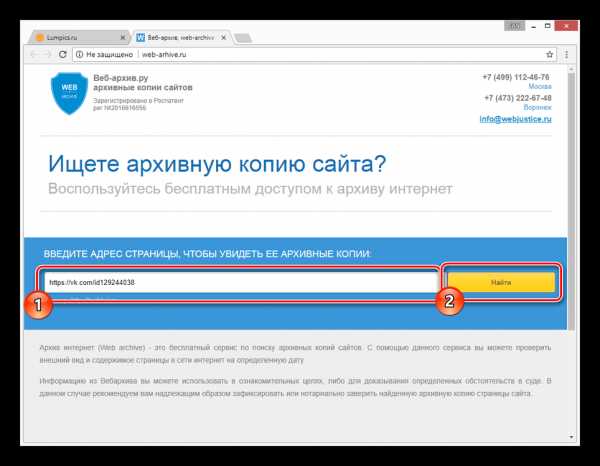
После этого под формой поиска появится поле «Результаты», где будут представлены все найденные копии страницы.
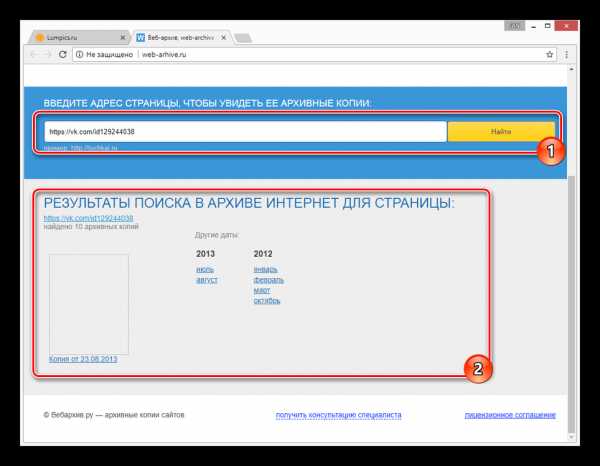
В списке «Другие даты» выберите колонку с нужным годом и кликните по наименованию месяца.
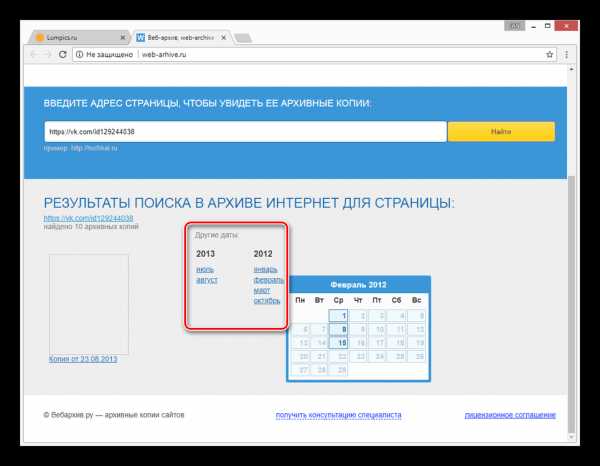
С помощью календаря кликните по одному из найденных чисел.
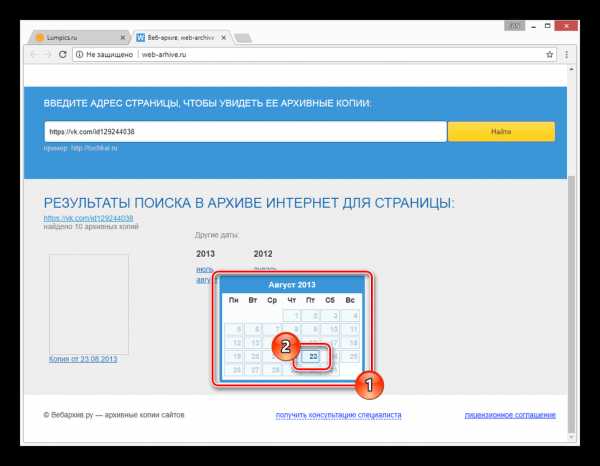
По завершении загрузки вам будет представлена анкета пользователя, соответствующая выбранной дате.
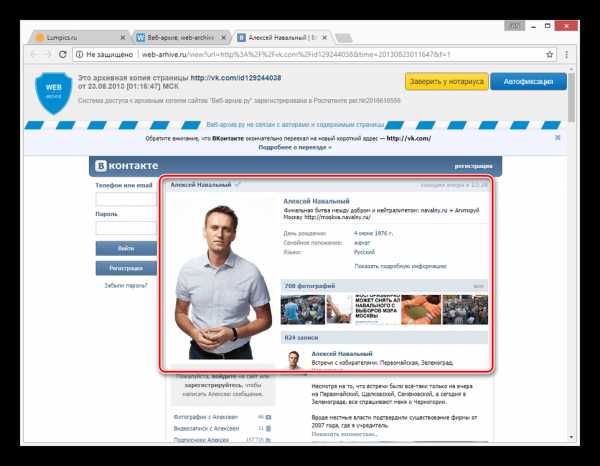
Как и в прошлом методе, все возможности сайта, кроме непосредственного просмотра информации, будут блокированы. Однако на сей раз содержимое полностью переведено на русский язык.
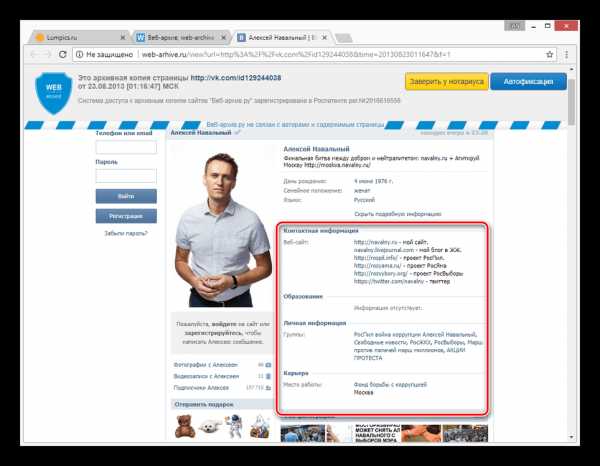
Вы также можете прибегнуть к еще одной статье на нашем сайте, рассказывающей о возможности просмотра удаленных страниц. Мы же завершаем данный способ и статью, так как изложенного материала более чем достаточно для просмотра ранней версии страницы ВКонтакте.
Мы рады, что смогли помочь Вам в решении проблемы.
Как удалить сайт из кэша
Чтобы ускорить индексирование страницы поисковиками, владельцы ресурсов удаляют из кэша старые версии. Так, Яндекс и Google не обходят стороной ссылки, которые уже прописаны у них системе. Обе системы проводят периодическую актуализация данных, но этим занимается робот. Из-за такой специфики обновление информации происходит дольше, чем при вмешательстве владельца сайта.
Чтобы удалить страницу из кэша Google, необходимо:
- Зайти в сервис Webmaster.
- Перейти в раздел меню “Удалить URL-адрес”.
- Нажать на кнопку “Временно скрыть”, чтобы страницы перестала отображаться в результатах поиска.
- Ввести адрес ссылки.
- Нажать кнопку “Продолжить”.
- Выбрать необходимый тип удаления, в данном случае — второй пункт.
- Подтвердить запрос.
- Дождаться, когда заявка перейдет из статуса “Ожидание” в “Выполнено”.
https://youtube.com/watch?v=3y43CPA6lUc
Заблокированный сайт — еще не приговор. Сервисы Яндекс и Гугл постоянно создают кэш всех ресурсов, поэтому пользователи смогут получить к ним доступ даже после удаления контента с серверов. Для этого не потребуется дополнительный софт. Открыть копию можно всего в 2 клика. При этом она будет соответствовать последней актуальной версии сайта. Страницы из кэша могут спасти веб-программистов, если изменения кода обрушили весь интерфейс, а вспомнить, как он должен выглядеть, не получается.
Этап первый: Файловая структура
Распаковка архива, способ №1: Файловый менеджер
Ознакомиться со всеми возможностями файлового менеджера вы можете в руководстве по панели управления хостингом. Более того, если дата резервной копии присутствует в списке доступных резервных копий, вы можете восстановить файловую структуру напрямую из нашей системы резервного копирования без выгрузки на аккаунт. Подробнее об этом можно узнать здесь: .
Откройте файловый менеджер и перейдите в корень аккаунта, нажав кнопку «Домашний FTP» в верхней панели управления. По созданному архиву кликните правой кнопкой и выберите пункт меню «Распаковать архив»:
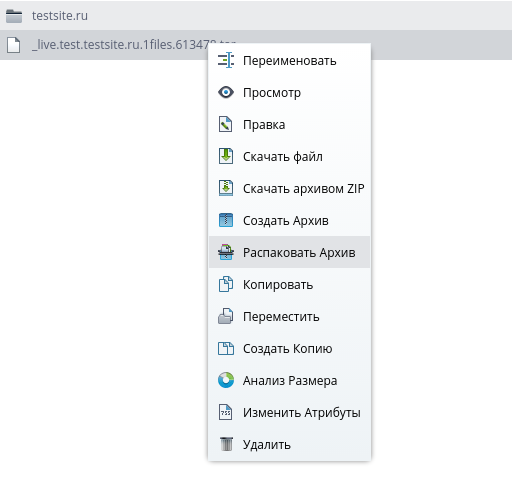
В появившемся окне укажите корень (/):
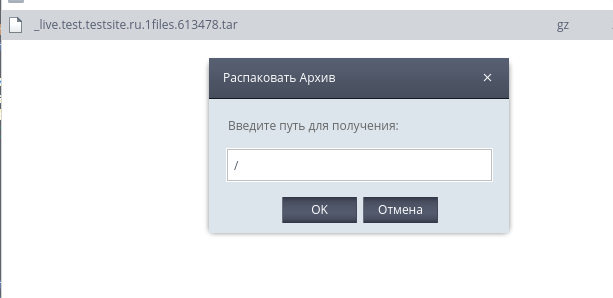
Нажмите «ОК», после чего ожидайте распаковки архива. После завершения процесса распаковки, процедуру восстановления файловой структуры можно считать выполненной.
Распаковка архива, способ №2: Терминал
Терминал — браузерная альтернатива SSH соединению, доступная в личном кабинете при включённом SSH. Включить SSH можно в главном разделе панели управления хостингом, переключив кнопку SSH в положение «ON» в блоке, расположенном с левой стороны. О том, как узнать имя архива, мы описали в начале данной статьи.
Имя архива вам уже известно. Теперь необходимо зайти в терминал, нажав на кнопку Terminal в нижнем левом углу панели управления хостингом (включите доступ к SSH, если Вы этого еще не сделали), и выполнить команду:
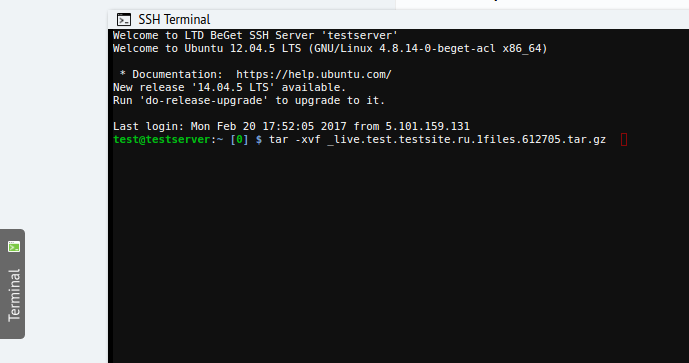
Эта команда распакует файлы в директорию, в которой хранились файлы на момент создания резервной копии и перезапишет существующие файлы. Напоминаем: те файлы, которые на момент создания резервной копии отсутствовали на вашем сайте, останутся в сохранности, поэтому перед распаковкой лучше очистить корневую директорию сайта путём удаления имеющихся файлов или переносом их в другую (временную) директорию.
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Статьи
Что такое веб-архив и зачем он нужен?
Веб-архив — история миллионов сайтов
Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Онлайн сервисы для копирования простых сайтов
В сети существуют сервисы, которые копируют лендинг, чистят и изменяют его. Нужно указать целевой сайт, а сервис его скачает, очистит скопированную страницу от лишнего кода и чужих ссылок. Клиент получит новый одностраничник в виде готового архива для загрузки на хостинг.
Примеры таких сервисов:
copysta.ru — вы указываете адрес «донора» и сервис полностью скачивает лендинг, очищает его от лишнего кода, меняются контакты, формы заявок перестраиваются на почту заказчика, устанавливается админка для управления лендингом на хостинге заказчика. Стоимость услуг: 1 500-3 000 рублей. В самый дорогой тариф входит редактирование контента, стилей, замена изображений с целью сделать новый лендинг уникальным;
7lend.club – этот сервис предлагает услуги от простого скачивания, до очистки кода, установки счетчиков и форм заказчика и уникализации контента. Стоимость от $8 до $50 за лендинг;
copyland.pro – предлагает сделать копию лендинга любой сложности с очисткой от старых контактов, ссылок, счетчиков веб статистики и перестройку реквизитов, форм и счетчиков для заказчика. Стоимость услуг от 500 рублей; xdan.ru/copysite/ позволяет сделать локальную копию сайта. При этом можно очистить HTML от счетчиков, заменить ссылки или домен в ссылках, заменять указанные слова, всего 11 настроек. Минимальная подписка — 75 рублей на 24 часа.
Это лишь примеры сервисов. Таких подобных можно найти сотни если поискать.
580 просмотров
Отказ от ответственности: Автор или издатель не публиковали эту статью для вредоносных целей. Вся размещенная информация была взята из открытых источников и представлена исключительно в ознакомительных целях а также не несет призыва к действию. Создано лишь в образовательных и развлекательных целях. Вся информация направлена на то, чтобы уберечь читателей от противозаконных действий. Все причиненные возможные убытки посетитель берет на себя. Автор проделывает все действия лишь на собственном оборудовании и в собственной сети. Не повторяйте ничего из прочитанного в реальной жизни. | Так же, если вы являетесь правообладателем размещенного на страницах портала материала, просьба написать нам через контактную форму жалобу на удаление определенной страницы, а также ознакомиться с инструкцией для правообладателей материалов. Спасибо за понимание.
А теперь подробно
1. Выделяем текст или его часть.
Подводим курсор (палочку) в самое начало текста, который нужно скопировать. Затем нажимаем на левую кнопку мышки и, не отпуская ее, как будто бы обводим строки. Когда они закрасятся каким-нибудь цветом (скорее всего, голубым), отпускаем кнопку мышки. Выделение при этом должно остаться.
2. Копируем то, что выделили.
Наводим курсор в любое место закрашенной части и нажимаем правую кнопку мышки. Появится список. При этом выделение должно остаться. В списке наводим на пункт «Копировать» и щелкаем по нему левой кнопкой мышки.
3. Открываем программу для вставки текста.
Это может быть Microsoft Word, WordPad, Блокнот или какая-то другая. Для ее открытия щелкаем по кнопке «Пуск» в нижнем левом углу экрана и из списка выбираем «Все программы».
Далее ищем пункт Microsoft Office и там выбираем Microsoft Office Word.
Если ничего подобного вы у себя не находите, откройте пункт «Стандартные» и выберите программу «WordPad» или «Блокнот».
4. Вставляем информацию в программу.
Когда программа откроется, нажимаем внутри нее, то есть по белой части, правой кнопкой мышки. Появится список, из которого выбираем пункт «Вставить».
Если все сделано правильно, то текст из интернета вставится в программу.
Картинки и фотографии обычно добавляются вместе с ним.
5. Сохраняем на компьютер.
Хоть информация и вставилась, но на компьютер она еще не записана. Чтобы это сделать, нужно нажать на кнопку «Файл» в приложении и выбрать «Сохранить» или «Сохранить как…».
Появится окошко, в котором нужно выбрать место в компьютере, куда следует записать данные.
Например, я хочу сохранить документ в Локальный диск D. Значит, выбираю диск D в этом окошке.
А если я хочу записать его сразу на флешку, то выбираю именно ее в этом окошке.
Кстати, прямо здесь, внутри, можно создать отдельную папку для текста.
После того как в окошке выбрано нужное место, обратите внимание на поле «Имя файла». В нем указано то название, которое система предлагает дать документу
Если оно не подходит, можно напечатать другое, более подходящее.
Когда место для файла выбрано и имя назначено, нажимаем кнопку «Сохранить».
Теперь полностью закрываем приложение и открываем то место на ПК, которое выбирали в окошке сохранения.
В моем случае это был Локальный диск D. Значит, открываю Пуск – Компьютер и захожу в диск D.
Там должен быть файл, открыв который, появится тот самый текст из интернета.
Как очистить текст от мусора
Зачастую скопированный текст добавляется в программу вместе с оформлением, какое было у него в интернете. Бывает, оно выглядит не очень симпатично.
Поправить это легко: нужно просто выделить текст (так же, как мы это делали при копировании) и нажать на вот такую кнопку вверху программы Word — она находится в закладке «Главная».
Сразу после этого у выделенных данных уберутся все эффекты.
P.S.
Это краткая инструкция по записи текста из интернета в компьютер. Если вы в чем-то не до конца разобрались, советую изучить подробную инструкцию вот по этой ссылке.
Как копировать текст: интересные способы и приёмы
1. Просто перепечатать, когда не могу скопировать текст с сайта
Как уже говорилось ранее, защищенный от копирования текст можно просто перепечатать с помощью выбранного текстового редактора. Если отрывок нужного текста сравнительно небольшой, этот способ может прийтись как нельзя кстати. Кроме того, в большинстве случаев, при использовании текста опубликованного на одном из интернет сайтов все равно приходится применять методы рейтинга (письменного пересказа текста, а значит, отрывок все равно придётся перепечатать от руки. В этом случае, выбранный текст можно тут же мысленно изменять и печатать в редакторе уже «отрерайченный» вариант.
Другие секреты: Как раздать вай-фай ( интернет) без роутера на телефон/ др. устройства
Если же отрывок текста слишком большой и перепечатать его вручную будет сложно, придется применить другие способы снятия защиты от копирования. Вот некоторые из них.
2. Как скопировать текст, если он не копируется с помощью открытия HTML
В настройках управления используемого браузера нужно найти подпункт «Вид» и избрать подпункт «Просмотр кода HTML». В некоторых современных браузерах эти операции можно заменить комбинацией клавиш «Ctrl +U ». Для ускорения поиска искомого текста, после открытия окошка с HTML- кодом следует нажимать клавиши «Ctrl + F» и в появившемся небольшом окошке поиска ввести несколько первых искомого текста и нажать команду «Enter».
После нахождения нужного текста, его останется лишь выделить курсором, скопировать его в буфер обмена командой «Ctrl + C» и вставить в выбранный текстовый редактор сочетанием клавиш «Ctrl + V». После этого, текст будет полностью готов к дальнейшей корректировке.
3. Сделать скриншот и пропустить через онлайн сервис для распознавания текста
Если нужный текст скопировать этим способом не удалось, скорее всего, это связано с тем, что данный текст сохранен в качестве изображения. Чтобы скопировать такой текст, нужно выделить нужную часть страницы и сделать ее скриншот в одном из графических редакторов. Есть хорошая, полезная программка, чтобы снимать скриншоты с экрана компьютера, если нужно, можете ее бесплатно скачать для себя — . Или вы можете воспользоваться для этой цели — программкой «Ножницы», которая установлена практически во всех операционных системах компьютеров.
Затем, полученный файл нужно пропустить через один из бесплатных онлайн сервисов, созданных для распознавания текста. В них достаточно прикрепить картинку или скриншот, выбрать язык распознавания и запустить процесс. Некоторые из них мы приводим ниже.
Это поможет подготовить нужный текст для дальнейшего копирования и использования по назначению.
4. Как копировать текст помощью Microsoft Word (Макрософт Ворд).
Для этого нужно скопировать адрес ссылки нужной страницы, открыть Microsoft Offis, нажать пункт «файл» и подпункт «открыть». После чего, в появившееся окно открытия нужно вставить http://…нужной странички и снова выбрать команду «открыть». В ответ на любые предупреждения Word нужно нажимать кнопку «OK»,т.о игнорируя запрос имени пользователя и пароля. После этого вся информация, с нужной странички защищенной от копирования будет доступна вам для редактирования и использования.
5. Как скопировать текст помощью отключения java-скриптов
Некоторые пользователи отмечают, что отключение java-скриптов также может помочь снять защиту от копирования. А значит, чтобы скопировать нужный текст, достаточно зайти в настройки браузера, выбрать подпункт «дополнительные настройки», отключить Java, вернуться на нужную страницу с текстом, обновить его и попытаться скопировать привычным сочетанием команд «Ctrl+C» и «Ctrl+V».
Успехов Вам в Ваших творческих проектах, дорогие друзья! Ваша команда ОПТИМУС ЖИЗНЬ.