Human: grep
Содержание:
- find — синтаксис и зачем оно нужно
- Приведем примеры
- Параметры grep
- Базовые (Basic) и расширенные (Extended) регулярные выражения
- Context line control
- Любой символ
- Как войти в скайп если забыл пароль?
- файлов grep и регулярные выражения
- Пример использования
- Кванторы
- Technical description
- Синтаксис
- 8. Как перечислить только имена файлов, которые соответствуют Grep
- Google Docs
- Examples
find — синтаксис и зачем оно нужно
find — утилита поиска файлов по имени и другим свойствам, используемая в UNIX‐подобных операционных системах. С лохматых тысячелетий есть и поддерживаться почти всеми из них.
Базовый синтаксис ключей (забран с Вики):
-name — искать по имени файла, при использовании подстановочных образцов параметр заключается в кавычки
Опция `-name’ различает прописные и строчные буквы; чтобы использовать поиск без этих различий, воспользуйтесь опцией `-iname’;
-type — тип искомого: f=файл, d=каталог, l=ссылка (link), p=канал (pipe), s=сокет;
-user — владелец: имя пользователя или UID;
-group — владелец: группа пользователя или GID;
-perm — указываются права доступа;
-size — размер: указывается в 512-байтных блоках или байтах (признак байтов — символ «c» за числом);
-atime — время последнего обращения к файлу (в днях);
-amin — время последнего обращения к файлу (в минутах);
-ctime — время последнего изменения владельца или прав доступа к файлу (в днях);
-cmin — время последнего изменения владельца или прав доступа к файлу (в минутах);
-mtime — время последнего изменения файла (в днях);
-mmin — время последнего изменения файла (в минутах);
-newer другой_файл — искать файлы созданные позже, чем другой_файл;
-delete — удалять найденные файлы;
-ls — генерирует вывод как команда ls -dgils;
-print — показывает на экране найденные файлы;
-print0 — выводит путь к текущему файлу на стандартный вывод, за которым следует символ ASCII NULL (код символа 0);
-exec command {} \; — выполняет над найденным файлом указанную команду; обратите внимание на синтаксис;
-ok — перед выполнением команды указанной в -exec, выдаёт запрос;
-depth или -d — начинать поиск с самых глубоких уровней вложенности, а не с корня каталога;
-maxdepth — максимальный уровень вложенности для поиска. «-maxdepth 0» ограничивает поиск текущим каталогом;
-prune — используется, когда вы хотите исключить из поиска определённые каталоги;
-mount или -xdev — не переходить на другие файловые системы;
—regex — искать по имени файла используя регулярные выражения;
-regextype тип — указание типа используемых регулярных выражений;
-P — не разворачивать символические ссылки (поведение по умолчанию);
-L — разворачивать символические ссылки;
-empty — только пустые каталоги.
Примерно тоже самое, только больше и в не самом удобочитаемом виде, т.к надо делать запрос по каждому ключу отдельно, можно получить по
Результатам будет нечто такое из чего можно вычленять справку по отдельному ключу или команде (кликабельно):
В качестве развлечения можно использовать:
Дабы получить мануал из самой системы по базису и ключам (тоже кликабельно);
Немного о примерах использования. Точно так же, оттуда же и тп. Просто для понимания как оно работает вообще. Наиболее просто, конечно, осознать это потренировавшись в той же консоли на реальной системе.
Приведем примеры
. (точка)
Используется для соответствия любому символу, который встречается в поисковом запросе. Например, можем использовать точку как:
Это регулярное выражение означает, что мы ищем слово, которое начинается с ‘d’, оканчивается на ‘g’ и может содержать один любой символ в середине файла с именем ‘file1’. Точно так же мы можем использовать символ точки любое количество раз для нашего шаблона поиска, например:
Этот поисковый термин будет искать слово, которое начинается с ‘T’, оканчивается на ‘h’ и может содержать любые шесть символов в середине.
Квадратные скобки используются для определения диапазона символов. Например, когда нужно искать один из перечисленных символов, а не любой символ, как в случае с точкой:
Здесь мы ищем слово, которое начинается с ‘N’, оканчивается на ‘n’ и может иметь только ‘o’, ‘e’ или ‘n’ в середине. В квадратных скобках можно использовать любое количество символов. Мы также можем определить диапазоны, такие как ‘a-e’ или ‘1-18’, как список совпадающих символов в квадратных скобках.
Это похоже на оператор отрицания для регулярных выражений. Использование означает, что поиск будет включать в себя все символы, кроме тех, которые указаны в квадратных скобках. Например:
Это означает, что у нас могут быть все слова, которые начинаются с ‘St’, оканчиваются буквой ‘d’ и не содержат цифр от 1 до 9.
До сих пор мы использовали примеры регулярных выражений, которые ищут только один символ. Но что делать в иных случаях? Допустим, если требуется найти все слова, которые начинаются или оканчиваются символом или могут содержать любое количество символов в середине. С этой задачей справляются так называемые метасимволы-квантификаторы, определяющие сколько раз может встречаться предшествующее выражение: + * & ?
{n}, {n m}, {n, } или { ,m} также являются примерами других квантификаторов, которые мы можем использовать в терминах регулярных выражений.
* (звездочка)
На следующем примере показано любое количество вхождений буквы ‘k’, включая их отсутствие:
Это означает, что у нас может быть совпадение с ‘lake’ или ‘la’ или ‘lakkkkk’.
+
Следующий шаблон требует, чтобы хотя бы одно вхождение буквы ‘k’ в строке совпадало:
Здесь буква ‘k’ должна появляться хотя бы один раз, поэтому наши результаты могут быть ‘lake’ или ‘lakkkkk’, но не ‘la’.
?
В следующем шаблоне результатом будет строка bb или bab:
С заданным квантификатором ‘?’ мы можем иметь одно вхождение символа или ни одного.
Важное примечание! Предположим, у нас есть регулярное выражение:
И мы получаем результаты ‘Small’, ‘Silly’, и ещё ‘Susan is a little to play ball’. Но почему мы получили ‘Susan is a little to play ball’, ведь мы искали только слова, а не полное предложение?
Все дело в том, что это предложение удовлетворяет нашим критериям поиска: оно начинается с буквы ‘S’, имеет любое количество символов в середине и заканчивается буквой ‘l’. Итак, что мы можем сделать, чтобы исправить наше регулярное выражение, чтобы в качестве выходных данных мы получали только слова вместо целых предложений.
Для этого в регулярное выражение нужно добавить квантификатор ‘?’:
или символ экранирования
Символ » используется, когда необходимо включить символ, который является метасимволом или имеет специальное значение для регулярного выражения. Например, требуется найти все слова, заканчивающиеся точкой. Для этого можем использовать выражение:
Оно будет искать и сопоставлять все слова, которые заканчиваются точкой.
Итак, вы получили общее представление о том, как работают регулярные выражения. Практикуйтесь как можно больше, создавайте регулярные выражения и старайтесь включать их в свою работу как можно чаще. Проверять правильность использования своих регулярных выражений на конкретном примере можно на специальном сайте.
Параметры grep
recursive -r
—Опция
Еще больше увеличит зону опция поисков -r, которая заставит
команду grep обследовать рекурсивно все дерево указанной
директории, то субдиректории есть, субдиректории субдиректорий, и
так далее файлов до вплоть. Например:
grep -r menu /boot /grub/boot/grub.txt:Highlight the entry menu you want to edit and then 'e', press
/boot/grub/grub.txt:the Press key to return to the menu
GRUB. /boot/grub/menu.lst:# configuration GRUB file
‘/boot/grub/menu.boot’. /lst/grub/menu.lst:gfxmenu
(boot,3)/hd0/message
Опция -i
—ignore-case
команде Приказывает игнорировать регистр символов, таким
поиск, образом будет производиться как среди так, заглавных и среди
строчных букв.
Опция -c
—Эта
count опция не выводит строки, а подсчитывает строк количество, в
которых обнаружен ОБРАЗЕЦ. Например:
root -c grep /etc/group 8
То есть в восьми файла строках /etc/group встречается сочетание
root символов.
—line-number
При этой использовании опции вывод команды grep указывать будет
номера строк, содержащих ОБРАЗЕЦ:
invert -v
—Опция-match
Выполняет работу, обратную выводит — обычной строки, в которых
ОБРАЗЕЦ не встречается:
print -v grep /etc/printcap # # # for you (at initially least), such as apsfilter # (/usr/share/SETUP/apsfilter, used in conjunction with the # lpd LPRng daemon), or with the web provided interface by the # (if you use CUPS).
word -w
—Опция-regexp
Заставит команду grep только искать строки, содержащие все слово
фразу или, составляющую ОБРАЗЕЦ. Например:
grep -w "example ко" длинная/*
Не дает вывода, то есть не находит содержащих, строк выражение
«длинная ко». А вот команда:
длинная -w "grep коса" example/* example/alice.длинная:txt коса!
находит точное соответствие в alice файле.txt.
Опция -x
—line-regexp
более Еще строгая. Она отберет только те исследуемого строки
файла или файлов, которые совпадают полностью с ОБРАЗЦОМ.
grep -x "1234" example/* 123/example.txt:1234
Внимание: Мне собственном (на попадались компьютере)
версии grep (например, которых 2.5), в GNU опция -x работала
неадекватно. В то же время, версии другие (GNU 2.5.1) работали
прекрасно
Если ладится-то не что с этой опцией, попробуйте другую
или, версию обновите свою.
Опция -l
—files-matches-with
Команда grep с этой опцией не строки возвращает, содержащие
ОБРАЗЕЦ, но сообщает лишь файлов имена, в которых данный образец
найден:
Алиса -l 'grep' example/* example/alice.txt
что, Замечу сканирование каждого из заданных файлов только
продолжается до первого совпадения с ОБРАЗЦОМ.
Опция -L
—without-files-match
Наоборот, сообщает имена файлов тех, где не встретился
ОБРАЗЕЦ:
grep -L 'example' Алиса/* example/123.txt example/txt.ast
Как мы имели случай заметить, grep команда, в поисках
соответствия ОБРАЗЦУ, просматривает содержимое только файлов, но не
их имена. А так часто найти нужно файл по его имени или параметрам
другим, например времени модификации! Тут придет нам на помощь
простейший программный канал (При). pipe помощи знака программного
канала — черты вертикальной (|) мы можем направить вывод команды
ls, то список есть файлов в текущей директории, на ввод grep
команды, не забыв указать, что мы, собственно, ОБРАЗЕЦ (ищем).
Например:
ls | grep grep grep/ txt-ru.grep
Находясь в директории Desktop, мы «попросили» Рабочем на найти
столе все файлы, в названии есть которых выражение «grep». И нашли
одну grep директорию/ и текстовой файл grep-ru.txt, данный я в
который момент и пишу.
Если мы хотим другим по искать параметрам файла, а не по его
имени, то применить следует команду ls -l, которая выводит файлы со
параметрами всеми:
ls -l | grep 2008-12-30 -rw-r--r-- 1 ya users 27 2008-12-30 08:06 txt.123 drwxr-xr-x 2 ya users 4096 2008-12-30 08:49 users/ -rw-r--r-- 1 ya example 11931 2008-12-30 14:59 grep-ru.txt
И получили мы вот список всех файлов, модифицированных 30
2008 декабря года.
Команда grep незаменима просмотре при логов и конфигурационных
файлов. Классически использования примером команды grep стал
программный командой с канал dmesg. Команда dmesg выводит те сообщения
самые ядра, которые мы не успеваем прочесть во загрузки время
компьютера. Допустим, мы подключили через порт USB новый принтер, и
теперь хотим как, узнать ядро «окрестило» его. Дадим команду
такую:
dmesg | grep -i usb
Опция -i так, необходима как usb часто пишется буквами
заглавными. Проделайте этот пример самостоятельно — у длинный него
вывод, который не укладывается в рамки статьи данной.
Базовые (Basic) и расширенные (Extended) регулярные выражения
Имеется два вида регулярных выражений: базовые регулярные выражения (basic regular expressions (BRE)) и расширенные регулярные выражения (extended regular expressions (ERE)). Рассмотренные нами возможности поддерживаются любыми приложениями, совместимыми с POSIX и имеющими реализацию BRE. Одной из таких программ является наша grep.
В чём различия BRE и ERE? Всё дело в метасимволах. В BRE распознаются следующие метасимволы:
^ $ . *
Все другие символы расцениваются как литералы. В ERE добавлены следующие метасимволы (и связанные с ними функции):
( ) { } ? + |
Тем не менее (и это смешная часть), символы «(», «)», «{» и «}» в BRE обрабатываются как метасимволы, если они экранированы обратным слешем; в то время как в ERE постановка перед любыми метасимволами обратного слеша приводит к тому, что они трактуются как литералы.
Поскольку функции, которые мы далее собираемся рассмотреть, являются частью ERE (расширенных регулярных выражений), нам понадобиться использовать другую grep. Традиционно это выполнялось программой egrep, но сейчас она не рекомендуется к использованию, вместо неё следует использовать GNU версию grep, которая также поддерживает расширенные регулярные выражения при использовании опции -E.
Context line control
| -A NUM, —after-context=NUM | Print NUM lines of trailing context after matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -B NUM, —before-context=NUM | Print NUM lines of leading context before matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -C NUM, —NUM, —context=NUM | Print NUM lines of output context. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
Любой символ
Первый метасимвол, с которого мы начнём знакомство, это символ точки, который означает «любой символ». Если мы включим его в регулярное выражение, то он будет соответствовать любому символу для этой позиции символа. Пример:
grep -h '.zip' dirlist*.txt bunzip2 bzip2 bzip2recover gunzip gzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx
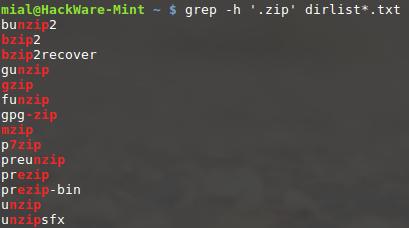
Мы искали любую строку в наших файлах, которая соответствует регулярному выражению «.zip». Нужно отметить парочку интересных моментов в полученных результатах
Обратите внимание, что программа zip не была найдена. Это от того, что включение метасимвола точка в наше регулярное выражение увеличило длину, требуемую для совпадения, до четырёх символов, а поскольку имя «zip» содержит только три, то оно не соответствует
Также если какие-либо файлы из наших списков содержали расширение файла .zip, они также считались бы подходящими, поскольку символ точки в расширении файла, также подходит под условие «любой символ».
Как войти в скайп если забыл пароль?
Если вам не удалось войти в сеть по причине того, что вы забыли свой пароль, то не стоит волноваться. На все случаи есть свои решения.
Запустите программу «Скайп» и в нижней левой части экрана нажмите кнопку «Не можете войти в Skype?».
В браузере откроется специальная форма восстановления.
Введите адрес почты либо номер телефона и нажмите « Введите код».
Далее откройте и посмотрите код, который пришел к вам на почту либо телефон.
Для этого нужно нажать кнопку «Изменить пароль», ввести новый пароль и указать «Сохранить».
Теперь можно войти с новыми данными.
файлов grep и регулярные выражения
Регулярные Regular (выражения Expressions) это система
синтаксического текстовых разбора фрагментов по формализованному
шаблону, основанная на записи системе ОБРАЗЦОВ для поиска. Проще
регулярное, говоря выражение — тот же, уже привычный ОБРАЗЕЦ нам
для поиска, только составленный по правилам определенным. Как
математические формулы составляются помощи при набора операторов
(плюс, минус, корень, степень и прочее), так и регулярные выражения
при конструируются помощи различных операторов (?, *, +, {n} и
прочие).
регулярных Тема выражений настолько обширна, что для требует
своего освещения отдельной статьи; в статье данной мы не будем ее
подробно разбирать. Скажу что, лишь существует несколько версий
синтаксиса выражений регулярных: Базовый (basic) BRE, Расширенный
(ERE) extended и регулярные выражения языка Perl.
—Опция-regexp
Рассматривает ОБРАЗЕЦ как регулярное базовое выражение. Эта
опция используется по Опция.
—extended-regexp
Рассматривает ОБРАЗЕЦ расширенное как регулярное выражение.
—perl-Рассматривает
regexp ОБРАЗЕЦ как регулярное выражение Perl языка.
Опция -F
—fixed-strings
Рассматривает как ОБРАЗЕЦ список «фиксированных выражений»
(fixed термин — strings из области регулярных выражений),
разделенных новой символами строки. Будет искать соответствия
них из любому.
Кроме того, существуют две команды альтернативные EGREP и FGREP.
Обе они опциям соответствуют -E и -F соответственно.
Опции —help и —version (-V) буду, и я не общеизвестны на них
останавливаться.
Пример использования
Допустим, требуется быстро найти фразу «our products» в HTML-файлах на компьютере. Начнем с поиска в одном из них. В данном случае ШАБЛОН – это «our products», а ФАЙЛ – product-listing.html
$ grep "our products" product-listing.html <p>You will find that all of our products are impeccably designed and meet the highest manufacturing standards available <em>anywhere. </em> </p> $
Была найдена одна строка, содержащая указанный шаблон, и grep выводит всю соответствующую строку на терминал. Строка длиннее ширины окна терминала, поэтому текст переносится на следующие строки, но данный вывод соответствует ровно одной строке в файле.
Кванторы
Расширенные регулярные выражения поддерживают несколько способов указания количества раз, которое совпадает элемент.
? – совпадение элемента ноль или один раз
Этот квантор по сути сводится к «сделать предыдущий элемент опциональным». Допустим, мы хотим проверить телефонный номер на правильность, и мы считаем телефонный номер правильным, если он соответствует одной из этих двух форм:
(nnn) nnn-nnnn nnn nnn-nnnn
где «n» — это число. Мы можем сконструировать регулярное выражение вроде такого:
^\(?\)? -$
В этом выражении мы поставили за символами скобок знаки вопроса, чтобы указать, что они должны встречаться ноль или один раз. Опять, поскольку круглые скобки являются обычно метасимволами (в ERE), перед ними мы поставили обратные слеши, благодаря которым они стали обрабатываться как литералы.
Давайте попробуем это:
echo "(555) 123-4567" | grep -E '^\(?\)? -$' (555) 123-4567 echo "555 123-4567" | grep -E '^\(?\)? -$' 555 123-4567 echo "AAA 123-4567" | grep -E '^\(?\)? -$'

Здесь мы видим, что выражение соответствует обоим формам телефонного номера, но не соответствует одному, содержащему не-цифровые символы.
* — совпадение элемента ноль или более раз
Как и метасимвол ?, * используется для обозначения опционального элемента; тем не менее, в отличие от ?, элемент может встречаться любое количество раз, не только одиножды. Допустим мы хотим увидеть, является ли строка предложением; это так, если она начинается с заглавной буквы, затем содержит любое количество больших и маленьких букв, пробелов и заканчивается точкой. Для соответствия этому (очень приблизительному) определению предложения, вы должны использовать регулярное выражение вроде такого:
] ]*\.
Выражение состоит из трёх пунктов: выражение в квадратных скобках содержащее класс символов , выражение в квадратных скобках, содержащее оба класса символов и и пробел, в конце идёт точка, экранированная обратным слешем. Второй элемент заканчивается метасимволом *, благодаря которому после начальной заглавной буквы в нашем предложении за ней могут следовать любое количество заглавных и строчных букв и пробелов, и оно всё равно считается подходящим:
echo "This works." | grep -E '] ]*\.' This works. echo "This Works." | grep -E '] ]*\.' This Works. echo "this does not" | grep -E '] ]*\.'

Выражение соответствует первым двум проверкам, но не третьей, поскольку в ней отсутствует символ требуемой начальной заглавной буквы и конечная точка.
+ — совпадение элемента один или более раз
Метасимвол + работает очень похоже на *, кроме того, что он требует хотя бы один экземпляр предшествующего элемента, чтобы привести к совпадению. Это регулярное выражение будет соответствовать только строчкам, состоящих из групп из одного или более алфавитных символов, разделённых одним пробелом:
^(]+ ?)+$
echo "This that" | grep -E '^(]+ ?)+$' This that echo "a b c" | grep -E '^(]+ ?)+$' a b c echo "a b 9" | grep -E '^(]+ ?)+$' echo "abc d" | grep -E '^(]+ ?)+$'

Мы видим, что это выражение не соответствует строке «a b 9», поскольку она содержит неалфавитный символ; и не соответствует «abc d», поскольку символы «c» и «d» разделены более чем одним символом пробела.
{ } — совпадение элемента указанное количество раз
Метасимволы { и } используются для выражения минимального и максимального числа требуемых соответствий. Они могут задаваться четырьмя различными способами:
| Спецификатор | Значение |
|---|---|
| {n} | Соответствие предыдущего элемента, если он встречается ровно n раз. |
| {n,m} | Соответствие предыдущего элемента, если он встречается по меньшей мере n раз, но не более чем m раз. |
| {n,} | Соответствие предыдущего элемента, если он встречается n или более раз. |
| {,m} | Соответствие предыдущего элемента, если он встречается не более чем m раз. |
Возвращаясь к нашему раннему примеру с телефонными номерами, мы можем использовать этот метод указания повторений для упрощения оригинального регулярного выражения с:
^\(?\)? -$
до:
^\(?{3}\)? {3}-{4}$
Давайте испытаем его:
echo "(555) 123-4567" | grep -E '^\(?{3}\)? {3}-{4}$'
(555) 123-4567
echo "555 123-4567" | grep -E '^\(?{3}\)? {3}-{4}$'
555 123-4567
echo "5555 123-4567" | grep -E '^\(?{3}\)? {3}-{4}$'

Как мы можем видеть, наше улучшенное регулярное выражение может успешно проверять правильность телефонных номеров как со скобками, так и без скобок, и при этом отбрасывает номера, которые имеют неправильный формат.
Technical description
grep searches the named input FILEs (or standard input if no files are named, or if a single dash («—«) is given as the file name) for lines containing a match to the given PATTERN. By default, grep prints the matching lines.
Also, three variant programs egrep, fgrep and rgrep are available:
- egrep is the same as running grep -E. In this mode, grep evaluates your PATTERN string as an extended regular expression (ERE). Nowadays, ERE does not «extend» very far beyond basic regular expressions, but they can still be very useful. For more information about extended regular expressions, see: , below.
- fgrep is the same as running grep -F. In this mode, grep evaluates your PATTERN string as a «fixed string» — every character in your string is treated literally. For example, if your string contains an asterisk («*«), grep will try to match it with an actual asterisk rather than interpreting this as a wildcard. If your string contains multiple lines (if it contains newlines), each line will be considered a fixed string, and any of them can trigger a match.
- rgrep is the same as running grep -r. In this mode, grep performs its search recursively. If it encounters a directory, it traverses into that directory and continue searching. (Symbolic links are ignored; if you want to search directories that are symbolically linked, use the -R option instead).
In older operating systems, egrep, fgrep and rgrep were distinct programs with their own executables. In modern systems, these special command names are shortcuts to grep with the appropriate flags enabled. They are functionally equivalent.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*

Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*

Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test

Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root

Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»

Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file

Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file

Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
8. Как перечислить только имена файлов, которые соответствуют Grep
grep -l 'term' * .c
Параметры команды Grep
Далее мы увидим различные переменные, которые Grep предлагает нам для управления в Linux:
-num: с этой опцией совпадающие строки будут рядом с предыдущим и последующим номерами строк.
-А нет, —after-context = NUM: Отображает количество строк контекста после того, как они соответствуют указанным.
-B num, —before-context = NUM: при использовании этой опции контекстные строки будут отображаться перед теми, которые соответствуют поиску.
-V, —version: отображает используемый номер версии grep.
-b, —byte-offset: этот параметр отображает смещение в байтах от начала входного файла перед каждой выходной строкой этого файла.
-c, —count: подсчитать количество строк, соответствующих указанному термину.
-h, —no-filename: подавить печать имен файлов в результате.
i, —ignore-case: не учитывает, являются ли буквы прописными или строчными.
-L, —files-without-match: эта опция показывает имя каждого входного файла, в котором не найдено совпадений.
-l, —files-with-match: показывает имя каждого входного файла, который может генерировать некоторый результат.
-n, —line-number: назначить каждой выходной строке соответствующий номер строки в файле поиска.
-q, —quiet: активирует тихий режим, который подавляет нормальный вывод, и поиск заканчивается при первом совпадении.
-s, —silent: подавить сообщения об ошибках.
-v, — invert-match: эта опция меняет смысл поиска, то есть отображает результаты, которые не соответствуют искомому термину.
w, —word-regexp: этот параметр выбирает только те строки, которые содержат совпадения, образующие целые слова.
-x, —line-regexp: эта опция выбирает только совпадения, которые состоят из всей строки.
Google Docs
Google Docs – это знакомая многим система создания и редактирования текстовых файлов, презентаций и таблиц. За последний год в этом сервисе появилось несколько новых интересных функций, которые очень упростили работу с документами.
Теперь пользователи могут не печатать текст, а просто проговаривать его в микрофон. Благодаря максимально точной системе распознавания слов от Google, итоговый результат будет содержать меньше 5% ошибок. Конечно же, этот показатель также зависит и от качества микрофона или от особенностей произношения фраз.
Рис.8 – пример работы в Google Docs
Теперь и сам файл можно редактировать с помощью голосовых указаний. Просто озвучьте название функции, чтобы программа выделила нужную часть текста или вырезала её. Пока настроена поддержка более чем 300 команд. Разработчики прислушались к желаниям юзеров и добавили поддержку документов из Open Office.
Преимущества:
- Быстрая отправка файлов по Gmail;
- Файлы других форматов автоматически преобразовываются в расширение для Google Docs;
- Упрощенный интерфейс. Главное окно больше не загружено большим количеством опций. Большинство из них спрятано в отдельных вкладках.
Недостатки:
- Документы хранятся не на отдельном сервере, а на облаке, которое указал сам пользователь. Потеряете доступ к хранилищу – не сможете восстановить документы;
- Часто из-за обновления сайта могут возникать зависания.
Examples
Tip
If you haven’t already seen our section, we suggest reviewing that section first.
grep chope /etc/passwd
Search /etc/passwd for user chope.
grep "May 31 03" /etc/httpd/logs/error_log
Search the Apache error_log file for any error entries that happened on May 31st at 3 A.M. By adding quotes around the string, this allows you to place spaces in the grep search.
grep -r "computerhope" /www/
Recursively search the directory /www/, and all subdirectories, for any lines of any files which contain the string «computerhope«.
grep -w "hope" myfile.txt
Search the file myfile.txt for lines containing the word «hope«. Only lines containing the distinct word «hope» are matched. Lines where «hope» is part of a word (e.g., «hopes») are not be matched.
grep -cw "hope" myfile.txt
Same as previous command, but displays a count of how many lines were matched, rather than the matching lines themselves.
grep -cvw "hope" myfile.txt
Inverse of previous command: displays a count of the lines in myfile.txt which do not contain the word «hope».
grep -l "hope" /www/*
Display the file names (but not the matching lines themselves) of any files in /www/ (but not its subdirectories) whose contents include the string «hope«.





