Методы строк в python
Содержание:
- Проверяет, что хотя бы один элемент в последовательности True.
- Поиск подстроки в строке
- Функции, которые когда-нибудь можно выучить
- Функция filter
- Поиск сопоставлений шаблонов
- Синтаксис
- Проверяет, что все элементы в последовательности True.
- Зачем использовать Python для поиска?
- Return Only Some Fields
- Задания для самоподготовки
- 5.7. More on Conditions¶
- Что вообще значит обойти дерево?
- Поисковые системы
- Что насчёт поиска в строке?
- Два вида сложности
- Методы для работы со строками
- Другие методы для работы со строками в Python
- Сложность строковых операций
- 5.3. Tuples and Sequences¶
- Узнайте, какие встроенные методы Python используются в строковых последовательностях
- To find the total occurrence of a substring
- 5 функций для отладки
Проверяет, что хотя бы один элемент в последовательности True.
Описание:
Функция возвращает , если какой-либо (любой) элемент в итерируемом объекте является истинным , в противном случае возвращает значение .
Если последовательность пуста, то функция возвращает .
Функция применяется для проверки истинности ЛЮБОГО из значений в итерируемом объекте и эквивалентна следующему коду:
def any(iterable):
for element in iterable
if element
return True
return False
Так же смотрите встроенную функцию .
В основном функция применяется в сочетании с оператором ветвления программы . Работу функции можно сравнить с оператором в Python, только работает с последовательностями:
>>> False or True or False # True >>> any() # True
Но между и в Python есть два основных различия:
- Синтаксис.
- Возвращаемое значение.
Функция всегда возвращает или .
>>> any() # True >>> any() # False
Оператор возвращает ПЕРВОЕ истинное значение, а если все значения , то ПОСЛЕДНЕЕ ложное значение.
>>> or 2 or 1 or or # 2 >>> or or '' # '' >>> bool( or 2 or 1 or or ) # True >>> bool( or or '') # False
Из всего сказанного можно сделать вывод, что для успешного использования функции необходимо в нее передавать последовательность, полученную в результате каких то вычислений/сравнений, элементы которого будут оцениваться как или . Это можно достичь применяя функцию или выражения-генераторы списков, используя в них встроенные функции языка, возвращающие значения, операции сравнения, оператор вхождения и оператор идентичности .
num = 1, 2.0, 3.1, 4, 5, 6, 7.9 # использование встроенных функций # на примере 'isdigit()' >>> str(x).isdigit() for x in num # # использование операции сравнения >>> x > 4 for x in num # # использование оператора вхождения `in` >>> '.' in str(x) for x in num # # использование оператора идентичности `in` >>> type(x) is int for x in num # # использование функции map() >>> list(map(lambda x x > 1, num)) False, True, True, True, True, True, True
Примеры проводимых проверок функцией .
Допустим у нас есть строка например с адресом и нам необходимо узнать, содержит ли адрес номер дома. Для этого разделим строку с адресом справа на лево методом по разделителю один раз.
>>> addr1 = '142100, г. Москва, ул. Свердлова, 15'
>>> addr2 = '142100, г. Москва, ул. Свердлова'
>>> any(map(str.isdigit, addr1.rsplit(' ',1)))
# True
>>> any(map(str.isdigit, addr2.rsplit(' ',1)))
# False
Второй пример с числовой последовательностью. Необходимо узнать, есть ли в последовательности числа больше определенного значения.
>>> num1 = range(, 20, 2) >>> num2 = range(, 15, 2) >>> any() # True >>> any() # False
Так же можно проверять строку на наличие, каких то определенных символов.
Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку:
• find(str): поиск подстроки str производится с начала строки и до её конца;
• find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск;
• find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!"
index = welcome.find("wor")
print(index) # 6
# ищем с десятого индекса
index = welcome.find("wor",10)
print(index) # 21
# ищем с 10-го по 15-й индекс
index = welcome.find("wor",10,15)
print(index) # -1
Функции, которые когда-нибудь можно выучить
Следующие встроенные функции Python определённо не бесполезны, но они более специализированы.
Эти функции вам, возможно, будут нужны, но также есть шанс, что вы никогда не прибегнете к ним в своём коде.
- : возвращает итератор (список, набор и т. д.);
- : возвращает , если аргумент является вызываемым;
- and : вместо них рекомендуется использовать генератор-выражения;
- : округляет число;
- : эта функция выполняет деление без остатка () и операцию по модулю () одновременно;
- , и : служат для отображения чисел в виде строки в двоичной, восьмеричной или шестнадцатеричной форме;
- : возвращает абсолютное значение числа (аргумент может быть целым или числом с плавающей запятой, если аргумент является комплексным числом, его величина возвращается);
- ;
- .
Функция filter
Следующая
аналогичная функция – это filter. Само ее название говорит, что
она возвращает элементы, для которых, переданная ей функция возвращает True:
filter(func, *iterables)
Предположим, у
нас есть список
a=1,2,3,4,5,6,7,8,9,10
из которого
нужно выбрать все нечетные значения. Для этого определим функцию:
def odd(x): return x%2
И далее, вызов
функции filter:
b = filter(odd, a) print(b)
На выходе
получаем итератор, который можно перебрать так:
print( next(b) ) print( next(b) ) print( next(b) ) print( next(b) )
Или, с помощью
цикла:
for x in b: print(x, end=" ")
Или же
преобразовать итератор в список:
b = list(filter(odd, a)) print(b)
Конечно, в
качестве функции здесь можно указывать лямбда-функцию и в нашем случае ее можно
записать так:
b = list(filter(lambda x: x%2, a))
И это бывает гораздо
удобнее, чем объявлять новую функцию.
Функцию filter можно применять
с любыми типами данных, например, строками. Пусть у нас имеется вот такой
кортеж:
lst = ("Москва", "Рязань1", "Смоленск", "Тверь2", "Томск")
b = filter(str.isalpha, lst)
for x in b:
print(x, end=" ")
и мы вызываем
метод строк isalpha, который
возвращает True, если в строке
только буквенные символы. В результате в консоли увидим:
Москва Смоленск
Тверь Томск
Поиск сопоставлений шаблонов
Давайте уделим немного времени тому, чтобы научиться основам сопоставлений шаблонов. Используя Python для поиска шаблона в строке, вы можете использовать функцию поиска также, как мы делали это в предыдущем разделе этой статьи. Вот пример:
Python
import re
text = «The ants go marching one by one»
strings =
for string in strings:
match = re.search(string, text)
if match:
print(‘Found «{}» in «{}»‘.format(string, text))
text_pos = match.span()
print(text)
else:
print(‘Did not find «{}»‘.format(string))
|
1 |
importre text=»The ants go marching one by one» strings=’the’,’one’ forstringinstrings match=re.search(string,text) ifmatch print(‘Found «{}» in «{}»‘.format(string,text)) text_pos=match.span() print(textmatch.start()match.end()) else print(‘Did not find «{}»‘.format(string)) |
В этом примере мы импортируем модуль re и создаем простую строку. Когда мы создаем список из двух строк, которые мы будем искать в главной строке. Далее мы делаем цикл над строками, которые хотим найти и запускаем для них поиск. Если есть совпадения, мы выводим их. В противном случае, мы говорим пользователю, что искомая строка не была найдена.
Существует несколько других функций, которые нужно прояснить в данном примере
Обратите внимание на то, что мы вызываем span. Это дает нам начальную и конечную позицию совпавшей строки
Если вы выведите text_pos, которому мы назначили span, вы получите кортеж на подобие следующего: (21, 24). В качестве альтернативы вы можете просто вызвать методы сопоставления, что мы и сделаем далее. Мы используем начало и конец для того, чтобы взять начальную и конечную позицию сопоставления, это должны быть два числа, которые мы получаем из span.
Синтаксис
Проверяет, что все элементы в последовательности True.
Описание:
Функция возвращает значение , если все элементы в итерируемом объекте — истинны, в противном случае она возвращает значение .
Если передаваемая последовательность пуста, то функция также возвращает .
Функция применяется для проверки на ВСЕХ значений в последовательности и эквивалентна следующему коду:
def all(iterable):
for element in iterable
if not element
return False
return True
Так же смотрите встроенную функцию
В основном функция применяется в сочетании с оператором ветвления программы . Работу функции можно сравнить с оператором в Python, только работает с последовательностями:
>>> True and True and True # True >>> True and False and True # False >>> all() # True >>> all() # False
Но между и в Python есть два основных различия:
- Синтаксис.
- Возвращаемое значение.
Функция всегда возвращает или (значение )
>>> all() # True >>> all(]) # False
Если в выражении все значения , то оператор возвращает ПЕРВОЕ истинное значение, а если все значения , то последнее ложное значение. А если в выражении присутствует значение , то ПЕРВОЕ ложное значение. Что бы добиться поведения как у функции , необходимо выражение с оператором обернуть в функцию .
>>> 3 and 1 and 2 and 6 # 6 >>> 3 and and 3 and [] # 0 >>> bool(3 and 1 and 2 and 6) # True >>> bool(3 and and 3 and []) # False
Из всего сказанного можно сделать вывод, что для успешного использования функции необходимо в нее передавать последовательность, полученную в результате каких то вычислений/сравнений, элементы которого будут оцениваться как или . Это можно достичь применяя функцию или выражения-генераторы списков, используя в них встроенные функции или методы, возвращающие значения, операции сравнения, оператор вхождения и оператор идентичности .
num = 1, 2.0, 3.1, 4, 5, 6, 7.9 # использование встроенных функций или # методов на примере 'isdigit()' >>> str(x).isdigit() for x in num # # использование операции сравнения >>> x > 4 for x in num # # использование оператора вхождения `in` >>> '.' in str(x) for x in num # # использование оператора идентичности `is` >>> type(x) is int for x in num # # использование функции map() >>> list(map(lambda x x > 1, num)) False, True, True, True, True, True, True
Примеры проводимых проверок функцией .
Допустим, у нас есть список чисел и для дальнейших операций с этой последовательностью необходимо знать, что все числа например положительные.
>>> num1 = range(1, 9) >>> num2 = range(-1, 7) >>> all() # True >>> all() # False
Или проверить, что последовательность чисел содержит только ЦЕЛЫЕ числа.
>>> num1 = 1, 2, 3, 4, 5, 6, 7 >>> num2 = 1, 2.0, 3.1, 4, 5, 6, 7.9 >>> all() # True >>> all() # False
Или есть строка с числами, записанными через запятую и нам необходимо убедится, что в строке действительно записаны только цифры. Для этого, сначала надо разбить строку на список строк по разделителю и проверить каждый элемент полученного списка на десятичное число методом . Что бы учесть правила записи десятичных чисел будем убирать точку перед проверкой строки на десятичное число.
>>> line1 = "1, 2, 3, 9.9, 15.1, 7" >>> line2 = "1, 2, 3, 9.9, 15.1, 7, девять" >>> all() # True >>> all() # False
Еще пример со строкой. Допустим нам необходимо узнать, есть ли в строке наличие открытой И закрытой скобки?
Зачем использовать Python для поиска?
Python очень удобочитаемый и эффективный по сравнению с такими языками программирования, как Java, Fortran, C, C++ и т. д. Одним из ключевых преимуществ использования Python для реализации алгоритмов поиска является то, что вам не нужно беспокоиться о приведении или явной типизации.
В Python большинство алгоритмов поиска, которые мы обсуждали, будут работать так же хорошо, если мы ищем строку. Имейте в виду, что понадобится внести изменения в код для алгоритмов, которые используют искомый элемент для числовых вычислений, например алгоритм интерполяционного поиска.
Python также подходит, если вы хотите сравнить производительность различных алгоритмов поиска для вашего dataset’а. Создание прототипа на Python проще и быстрее, потому что вы можете сделать больше с меньшим количеством строк кода.
Чтобы сравнить производительность наших реализованных алгоритмов, в Python мы можем использовать библиотеку time:
import time start = time.time() # вызовите здесь функцию end = time.time() print(start-end)
Return Only Some Fields
The second parameter of the method
is an object describing which fields to include in the result.
This parameter is optional, and if omitted, all fields will be included in
the result.
Example
Return only the names and addresses, not the _ids:
import pymongomyclient = pymongo.MongoClient(«mongodb://localhost:27017/»)
mydb = myclientmycol = mydbfor x in mycol.find({},{ «_id»: 0, «name»: 1, «address»: 1 }):
print(x)
You are not allowed to specify both 0 and 1 values in the same object (except
if one of the fields is the _id field). If you specify a field with the value 0, all other fields get the value 1,
and vice versa:
Example
This example will exclude «address» from the result:
import pymongomyclient = pymongo.MongoClient(«mongodb://localhost:27017/»)
mydb = myclientmycol = mydbfor x in mycol.find({},{ «address»: 0 }):
print(x)
Example
You get an error if you specify both 0 and 1 values in the same object
(except if one of the fields is the _id field):
import pymongomyclient = pymongo.MongoClient(«mongodb://localhost:27017/»)
mydb = myclientmycol = mydbfor x in mycol.find({},{ «name»: 1, «address»: 0 }):
print(x)
❮ Previous
Next ❯
Задания для самоподготовки
1. Поставить в
соответствие следующим английским символам русские буквы:
h – х, e – е, l – л, o – о, w – в, r – р, d – д
и преобразовать строку «hello world!» в русские символы.
2. Дан текст:
t = «»»Куда ты скачешь
гордый конь,
И
где опустишь ты копыта?
О
мощный властелин судьбы!
Не
так ли ты над самой бездной,
На высоте, уздой железной
Россию
поднял на дыбы?»»»
Необходимо
выделить каждое второе слово из этого стихотворения и представить результат в
виде упорядоченного списка. (Подумайте как реализовать алгоритм с наименьшими
затратами по памяти).
3. Реализовать
алгоритм для нахождения всех делителей натурального числа N. Число N вводится с
клавиатуры. Для начала можно реализовать простым перебором всех N возможных чисел
(делителей). Затем, подумайте, как можно оптимизировать по скорости этот
алгоритм.
Видео по теме
Python 3 #1: установка и запуск интерпретатора языка
Python 3 #2: переменные, оператор присваивания, типы данных
Python 3 #3: функции input и print ввода/вывода
Python 3 #4: арифметические операторы: сложение, вычитание, умножение, деление, степень
Python 3 #5: условный оператор if, составные условия с and, or, not
Python 3 #6: операторы циклов while и for, операторы break и continue
Python 3 #7: строки — сравнения, срезы строк, базовые функции str, len, ord, in
Python 3 #8: методы строк — upper, split, join, find, strip, isalpha, isdigit и другие
Python 3 #9: списки list и функции len, min, max, sum, sorted
Python 3 #10: списки — срезы и методы: append, insert, pop, sort, index, count, reverse, clear
Python 3 #11: списки — инструмент list comprehensions, сортировка методом выбора
Python 3 #12: словарь, методы словарей: len, clear, get, setdefault, pop
Python 3 #13: кортежи (tuple) и операции с ними: len, del, count, index
Python 3 #14: функции (def) — объявление и вызов
Python 3 #15: делаем «Сапер», проектирование программ «сверху-вниз»
Python 3 #16: рекурсивные и лямбда-функции, функции с произвольным числом аргументов
Python 3 #17: алгоритм Евклида, принцип тестирования программ
Python 3 #18: области видимости переменных — global, nonlocal
Python 3 #19: множества (set) и операции над ними: вычитание, пересечение, объединение, сравнение
Python 3 #20: итераторы, выражения-генераторы, функции-генераторы, оператор yield
Python 3 #21: функции map, filter, zip
Python 3 #22: сортировка sort() и sorted(), сортировка по ключам
Python 3 #23: обработка исключений: try, except, finally, else
Python 3 #24: файлы — чтение и запись: open, read, write, seek, readline, dump, load, pickle
Python 3 #25: форматирование строк: метод format и F-строки
Python 3 #26: создание и импорт модулей — import, from, as, dir, reload
Python 3 #27: пакеты (package) — создание, импорт, установка (менеджер pip)
Python 3 #28: декораторы функций и замыкания
Python 3 #29: установка и порядок работы в PyCharm
Python 3 #30: функция enumerate, примеры использования
5.7. More on Conditions¶
The conditions used in and statements can contain any
operators, not just comparisons.
The comparison operators and check whether a value occurs
(does not occur) in a sequence. The operators and compare
whether two objects are really the same object; this only matters for mutable
objects like lists. All comparison operators have the same priority, which is
lower than that of all numerical operators.
Comparisons can be chained. For example, tests whether is
less than and moreover equals .
Comparisons may be combined using the Boolean operators and , and
the outcome of a comparison (or of any other Boolean expression) may be negated
with . These have lower priorities than comparison operators; between
them, has the highest priority and the lowest, so that is equivalent to . As always, parentheses
can be used to express the desired composition.
The Boolean operators and are so-called short-circuit
operators: their arguments are evaluated from left to right, and evaluation
stops as soon as the outcome is determined. For example, if and are
true but is false, does not evaluate the expression
. When used as a general value and not as a Boolean, the return value of a
short-circuit operator is the last evaluated argument.
It is possible to assign the result of a comparison or other Boolean expression
to a variable. For example,
>>> string1, string2, string3 = '', 'Trondheim', 'Hammer Dance' >>> non_null = string1 or string2 or string3 >>> non_null 'Trondheim'
Что вообще значит обойти дерево?
Поскольку деревья — это разновидность графа, их обход, иначе называемый поиск по дереву, является видом обхода графа. Тем не менее для дерева этот процесс отличается меньшей масштабностью.
Обход дерева обычно известен как проверка (посещение) или обновление каждого узла по одному разу без повторений. Поскольку все узлы связаны рёбрами, начинаем мы всегда с корневого. Это означает, что нельзя произвольно обратиться к любому узлу дерева.
К выполнению обхода существует три подхода:
- прямой;
- симметричный;
- обратный.
Прямой обход
В этом способе мы сначала считываем данные с корневого узла, затем перемещаемся к левому поддереву, а потом к правому. В связи с этим посещаемые нами узлы (а также вывод их данных) следуют тому же шаблону, в котором сначала мы выводим данные корневого узла, затем данные его левого поддерева, а затем правого.
Алгоритм:
Прямой обход
Мы начинаем с корневого узла и, следуя прямому порядку обхода, сначала посещаем сам этот узел, а затем переходим к его левому поддереву, которое обходим по тому же принципу. Это продолжается, пока все узлы не будут посещены. В итоге порядок вывода будет таким: .
Симметричный обход
При симметричном обходе мы проходим по пути к самому левому потомку, затем возвращаемся к корню, посещаем его и следуем к правому потомку.
Алгоритм:
Симметричный обход
Начав от корневого узла 4, мы рекурсивно перебираем его левое поддерево, используя такой же симметричный порядок, затем посещаем сам корневой узел и далее перебираем правое поддерево.
Обратный обход
При обратном подходе мы сначала посещаем левого потомка, затем правого и по завершении обхода поддеревьев считываем корень.
Алгоритм:
Обратный обход
Становится ясно, что алгоритмы классифицируются на основе последовательности посещения узлов.
Здесь я снова упомяну, что есть две основных техники, которые мы можем использовать для обхода и посещения каждого узла исключительно по одному разу: поиск в глубину или поиск в ширину.
Поисковые системы
Что насчёт поиска в строке?
Самое быстрое — проверить, начинается ли (заканчивается ли) строка с выбранных символов. Для этого в Python предусмотрены специальные строковые методы.
Для поиск подстроки в произвольном месте есть метод с говорящим названием . Он вернет индекс начала найденного вхождения подстроки в строку, либо -1, если ничего не найдено.
Для сложных случаев, когда нужно найти не конкретную последовательность символов, а некий шаблон, помогут регулярные выражения. Они заслуживают отдельной статьи. Глубокого знания регулярок на собеседованиях не требуется, достаточно знать про них, уметь написать несложное выражение и прочитать чуть более сложное. Например, такое:
Два вида сложности
У каждого алгоритма есть временнáя и она же вычислительная сложность (time complexity) — сколько операций нужно выполнить. Также у алгоритма есть затраты памяти (space complexity) — сколько дополнительной RAM ему требуется для работы.
Очень часто эти две величины взаимосвязаны. Например, вас могут попросить уменьшить затраты по памяти, но за это придется заплатить большим количеством вычислений.
Если вы видите два пути решения с различными компромиссами время/память, обязательно проговорите с интервьюером, какой из них предпочтительнее. Интервьюер оценивает, как вы думаете
Поэтому дать понять, что вы делаете осознанный выбор на развилке — часто даже более важно, чем свернуть в нужную сторону
Методы для работы со строками
Кроме функций, для работы со строками есть немало методов:
- – возвращает индекс первого вхождения подстроки в s или -1 при отсутствии. Поиск идет в границах от до ;
- – аналогично, но возвращает индекс последнего вхождения;
- – меняет последовательность символов на новую подстроку ;
- – разбивает строку на подстроки при помощи выбранного разделителя x;
- – соединяет строки в одну при помощи выбранного разделителя x;
- – убирает пробелы с обеих сторон;
- – убирает пробелы только слева или справа;
- – перевод всех символов в нижний регистр;
- – перевод всех символов в верхний регистр;
- – перевод первой буквы в верхний регистр, остальных – в нижний.
Примеры использования:
Другие методы для работы со строками в Python
В языке Пайтон имеется большое кол-во различных методов для работы со строками. Если рассматривать их все в этой статье, то она может увеличить раза в три, а то и больше. Подробное описание работы всех методов можно найти в официальной документации к языку на сайте https://python.org/
Сложность строковых операций
Нет необходимости заучивать сложность каждой операции. Достаточно помнить, что большинство операций со строками «под капотом» делают посимвольную обработку. Если каждый символ обрабатывается за константное время O(1), то итоговая временная сложность будет O(n).
Трюк в том, чтобы понять:
- Сколько итераций цикла нужно пройти для получения результата? Иначе говоря, что есть n?
- В каких случаях цикл не нужен, либо наоборот, недостаточен.
| Действие | Временная сложность |
| a == b | O(n), где n — размер меньшей строки |
| a.startswith(b) | O(b) |
| s = «».join(arr) | O(s) |
| s = a + b | O(s) |
| s.split(«, «) | O(s) |
| b = a | O(1) |
| b = a | O(k) |
| b = a | O(1), т.к. мы просто создаем второй указатель на ту же строку |
| b = a | O(a). Это пример с подвохом. Такой трюк часто используется для создания независимой копии списка. Создать так копии строк можно, но бессмысленно, т.к. строки неизменяемы. Помимо времени, мы также расходуем лишние O(n) памяти. |
| a.find(b) | Для поиска подстроки используется специальный алгоритм, эффективность которого зависит от данных. В среднем на случайных строках можно ожидать O(a). В худшем случае — O(a*b), как у тривиального поиска (в цикле по a делаем сравнение подстроки с b) |
| re.match(expression, a) | Регулярные выражения работают медленнее поиска, но зависимость от длины строки как правило линейна, т.е. O(a). |
5.3. Tuples and Sequences¶
We saw that lists and strings have many common properties, such as indexing and
slicing operations. They are two examples of sequence data types (see
). Since Python is an evolving language, other sequence data
types may be added. There is also another standard sequence data type: the
tuple.
A tuple consists of a number of values separated by commas, for instance:
>>> t = 12345, 54321, 'hello!' >>> t 12345 >>> t (12345, 54321, 'hello!') >>> # Tuples may be nested: ... u = t, (1, 2, 3, 4, 5) >>> u ((12345, 54321, 'hello!'), (1, 2, 3, 4, 5)) >>> # Tuples are immutable: ... t = 88888 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> # but they can contain mutable objects: ... v = (, 3, 2, 1]) >>> v (, )
As you see, on output tuples are always enclosed in parentheses, so that nested
tuples are interpreted correctly; they may be input with or without surrounding
parentheses, although often parentheses are necessary anyway (if the tuple is
part of a larger expression). It is not possible to assign to the individual
items of a tuple, however it is possible to create tuples which contain mutable
objects, such as lists.
Though tuples may seem similar to lists, they are often used in different
situations and for different purposes.
Tuples are , and usually contain a heterogeneous sequence of
elements that are accessed via unpacking (see later in this section) or indexing
(or even by attribute in the case of ).
Lists are , and their elements are usually homogeneous and are
accessed by iterating over the list.
A special problem is the construction of tuples containing 0 or 1 items: the
syntax has some extra quirks to accommodate these. Empty tuples are constructed
by an empty pair of parentheses; a tuple with one item is constructed by
following a value with a comma (it is not sufficient to enclose a single value
in parentheses). Ugly, but effective. For example:
>>> empty = ()
>>> singleton = 'hello', # <-- note trailing comma
>>> len(empty)
>>> len(singleton)
1
>>> singleton
('hello',)
The statement is an example of tuple packing:
the values , and are packed together in a tuple.
The reverse operation is also possible:
>>> x, y, z = t
Узнайте, какие встроенные методы Python используются в строковых последовательностях
Строка — это последовательность символов. Встроенный строковый класс в Python представлен строками, использующими универсальный набор символов Unicode. Строки реализуют часто встречающуюся последовательность операций в Python наряду с некоторыми дополнительными методами, которые больше нигде не встречаются. На картинке ниже показаны все эти методы:
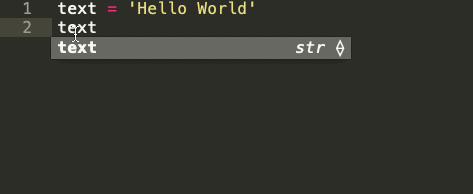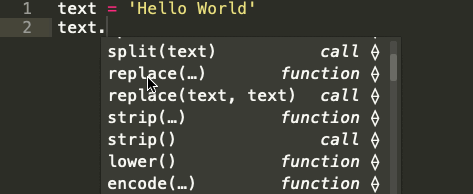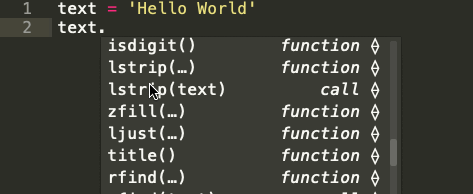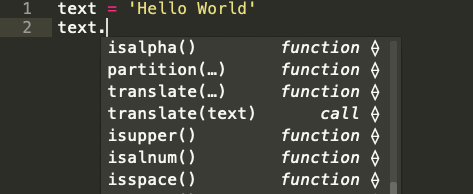 Встроенные строковые функции в Python
Встроенные строковые функции в Python
Давайте узнаем, какие используются чаще всего
Важно заметить, что все строковые методы всегда возвращают новые значения, не меняя исходную строку и не производя с ней никаких действий
Код для этой статьи можно взять из соответствующего репозитория Github Repository.
1. center( )
Метод выравнивает строку по центру. Выравнивание выполняется с помощью заданного символа (пробела по умолчанию).
Синтаксис
, где:
- length — это длина строки
- fillchar—это символ, задающий выравнивание
Пример

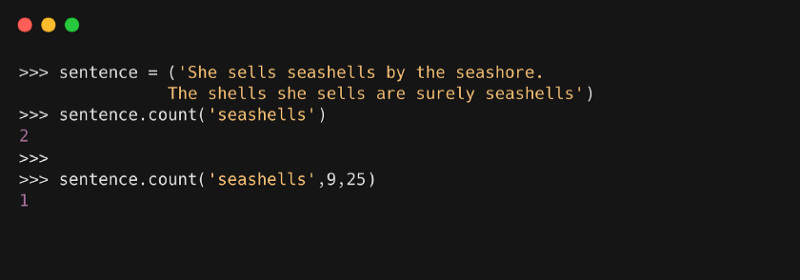
2. count( )
Метод возвращает счёт или число появлений в строке конкретного значения.
Синтаксис
, где:
- value — это подстрока, которая должна быть найдена в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
3. find( )
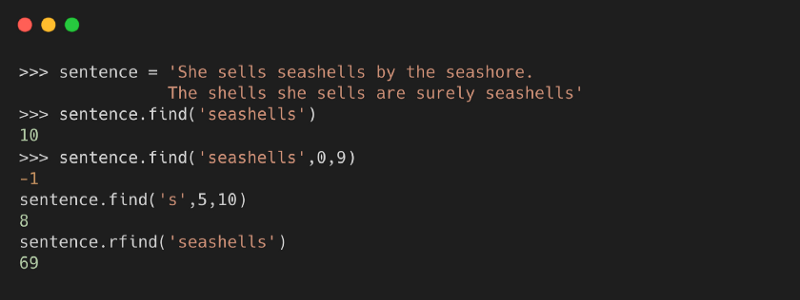
Метод возвращает наименьшее значение индекса конкретной подстроки в строке. Если подстрока не найдена, возвращается -1.
Синтаксис
, где:
- value или подстрока, которая должна быть найдена в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
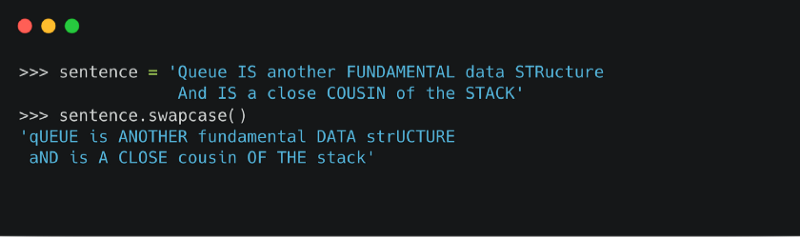
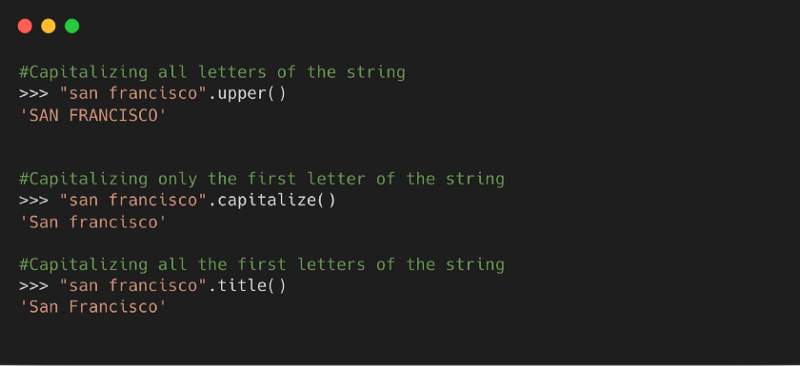
Метод возвращает копию строки, преобразуя все заглавные буквы в строчные, и наоборот.
Синтаксис
Пример
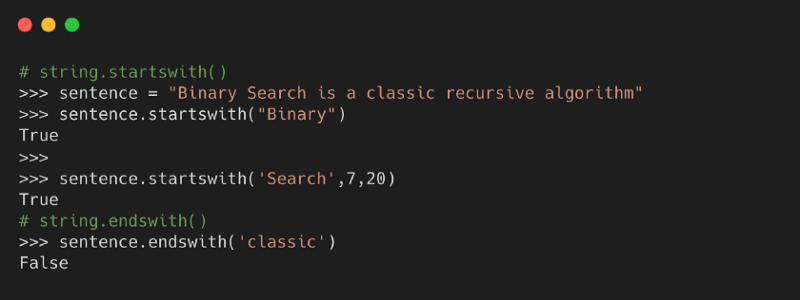
5. startswith( ) and endswith( )
Метод возвращает True, если строка начинается с заданного значения. В противном случае возвращает False.
С другой стороны, функция возвращает True, если строка заканчивается заданным значением. В противном случае возвращает False.
Синтаксис
- value — это искомая строка в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
6. split( )
Метод возвращает список слов в строке, где разделителем по умолчанию является пробел.
Синтаксис
- sep: разделитель, используемый для разделения строки. Если не указано иное, разделителем по умолчанию является пробел
- maxsplit: обозначает количество разделений. Значение по умолчанию -1, что значит «все случаи»
Пример
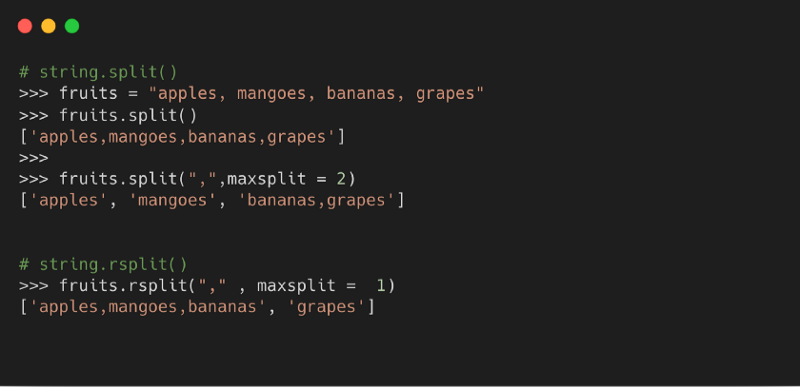
7. Строка заглавными буквами
Синтаксис
Синтаксис
Синтаксис
Пример
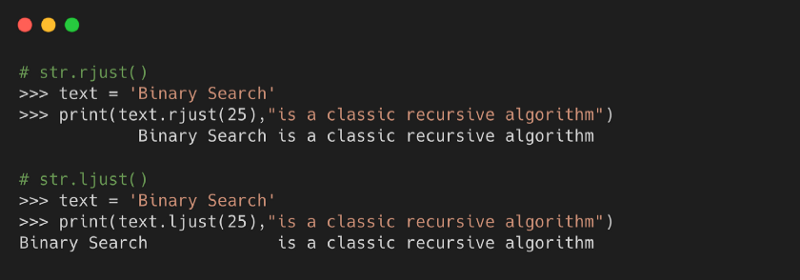
8. ljust( ) и rjust( )
С помощью заданного символа (по умолчанию пробел) метод возвращает вариант выбранной строки с левым выравниванием. Метод rjust() выравнивает строку вправо.
Синтаксис
- length: длина строки, которая должна быть возвращена
- character: символ для заполнения незанятого пространства, по умолчанию являющийся пробелом
Пример
9. strip( )
Метод возвращает копию строки без первых и последних символов. Эти отсутствующие символы — по умолчанию пробелы.
Синтаксис
character: набор символов для удаления
- : удаляет символы с начала строки.
- : удаляет символы с конца строки.
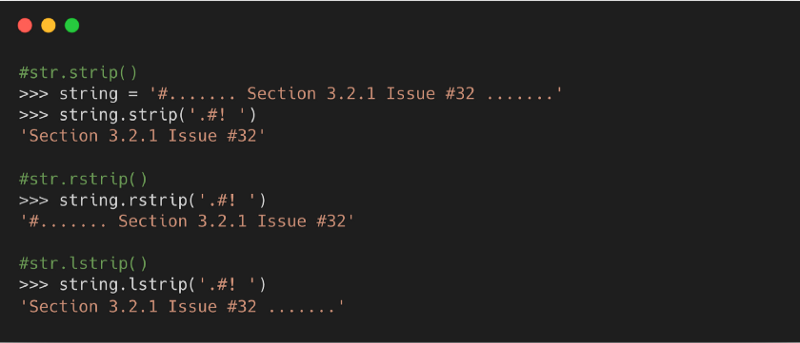
10. zfill( )
Метод zfill() добавляет нули в начале строки. Длина возвращаемой строки зависит от заданной ширины.
Синтаксис
width: указывает длину возвращаемой строки. Нули не добавляются, если параметр ширины меньше длины первоначальной строки.
Пример

Заключение
В статье мы рассмотрели лишь некоторые встроенные строковые методы в Python. Есть и другие, не менее важные методы, с которыми при желании можно ознакомиться в соответствующей документации Python.
- PEG парсеры и Python
- Популярные лайфхаки для Python
- Овладей Python, создавая реальные приложения. Часть 1
Перевод статьи Parul PandeyUseful String Method
To find the total occurrence of a substring
To find the total number of times the substring has occurred in the given string we will make use of find() function. Will loop through the string using for-loop from 0 till the end of the string. Will make use of startIndex parameter for find().
Variables startIndex and count will be initialized to 0. Inside for –loop will check if the substring is present inside the string given using find() and startIndex as 0.
The value returned from find() if not -1, will update the startIndex to the index where the string is found and also increment the count value.
Here is the working example:
my_string = "test string test, test string testing, test string test string"
startIndex = 0
count = 0
for i in range(len(my_string)):
k = my_string.find('test', startIndex)
if(k != -1):
startIndex = k+1
count += 1
k = 0
print("The total count of substring test is: ", count )
Output:
The total count of substring test is: 6
Summary
- The Python string find() method helps to find the index of the first occurrence of the substring in the given string. It will return -1 if the substring is not present.
- The parameters passed to find() method are substring i.e the string you want to search for, start, and end. The start value is 0 by default, and the end value is the length of the string.
- You can search the substring in the given string and specify the start position, from where the search will begin. The start parameter can be used for the same.
- Using the start and end parameter, we will try to limit the search, instead of searching the entire string.
- The Python function rfind() is similar to find() function with the only difference is that rfind() gives the highest index for the substring given and find() gives the lowest i.e the very first index. Both rfind() and find() will return -1 if the substring is not present.
- The Python string index() is yet another function that will give you the position of the substring given just like find(). The only difference between the two is, index() will throw an exception if the substring is not present in the string and find() will return -1.
- We can make use of find() to find the count of the total occurrence of a substring in a given string.
5 функций для отладки
Эти функции часто игнорируются, но будут полезны для отладки и устранения неисправностей кода.
breakpoint
Если нужно приостановить выполнение кода и перейти в командную строку Python, эта функция вам пригодится. Вызов перебросит вас в отладчик Python.
Эта встроенная функция была добавлена в Python 3.7, но если вы работаете в более старых версиях, можете получить тот же результат с помощью .
dir
Эта функция может использоваться в двух случаях:
- просмотр списка всех локальных переменных;
- просмотр списка всех атрибутов конкретного объекта.
Из примера можно увидеть локальные переменные сразу после запуска и после создания новой переменной .
Если в передать созданный список , на выходе можно увидеть все его атрибуты.
В выведенном списке атрибутов можно увидеть его типичные методы (, , и т. д.) , а также множество более сложных методов для перегрузки операторов.
vars
Эта функция является своего рода смесью двух похожих инструментов: и .
Когда вызывается без аргументов, это эквивалентно вызову , которая показывает словарь всех локальных переменных и их значений.
Когда вызов происходит с аргументом, получает доступ к атрибуту , который представляет собой словарь всех атрибутов экземпляра.
Перед использованием было бы неплохо сначала обратиться к .
type
Эта функция возвращает тип объекта, который вы ей передаете.
Тип экземпляра класса есть сам класс.
Тип класса — это его метакласс, обычно это .
Атрибут даёт тот же результат, что и функция , но рекомендуется использовать второй вариант.
Функция , кроме отладки, иногда полезна и в реальном коде (особенно в объектно-ориентированном программировании с наследованием и пользовательскими строковыми представлениями).
Обратите внимание, что при проверке типов обычно вместо используется функция. Также стоит понимать, что в Python обычно не принято проверять типы объектов (вместо этого практикуется утиная типизация)
help
Если вы находитесь в Python Shell или делаете отладку кода с использованием , и хотите знать, как работает определённый объект, метод или атрибут, функция поможет вам.
В действительности вы, скорее всего, будете обращаться за помощью к поисковой системе. Но если вы уже находитесь в Python Shell, вызов будет быстрее, чем поиск документации в Google.





